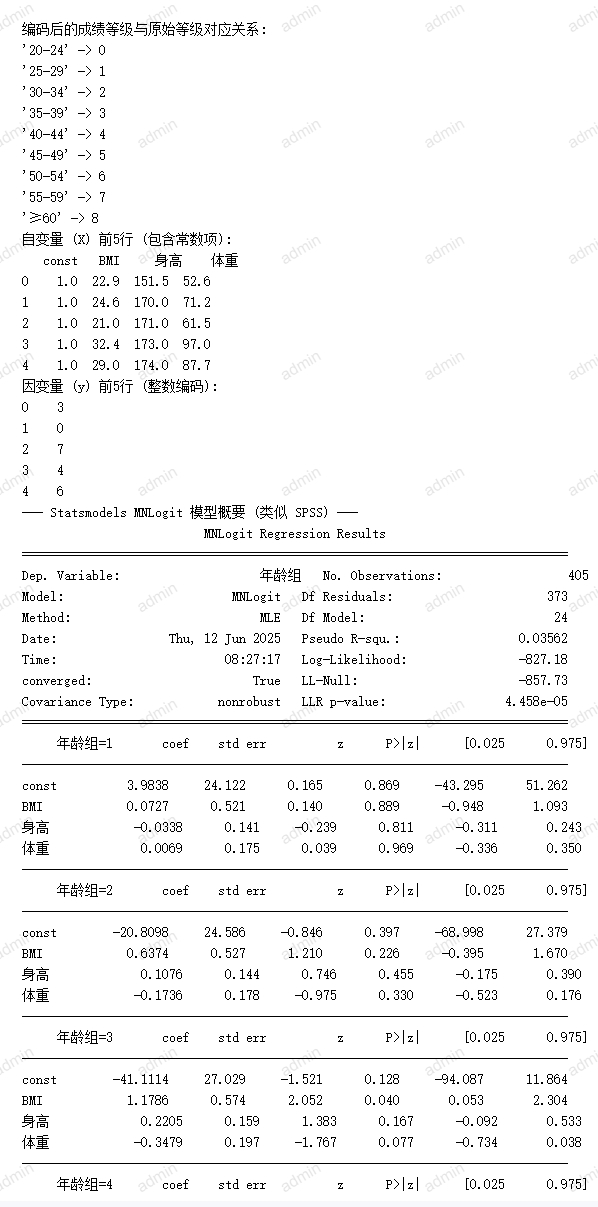
# 平台简介
临床大数据中心及科研应用平台是服务于医疗科研项目的数据管理、分析和应用平台。主要包括以下功能:
- 项目管理:涵盖项目生命周期的创建、立项、过程和结项管理,包括了项目信息、文档、成员、数据集、分析结果、项目成果等管理。
- 数据管理:覆盖了数据集成、数据ETL、数据管理、数据质量、数据安全等环节的数据生命周期整体管理。
- 数据应用:对于医疗科研形成的可共享的数据成果形成数据应用,方便成果的共享和复用。
- 系统管理:提供平台级的用户权限、基础数据、日志等管理。
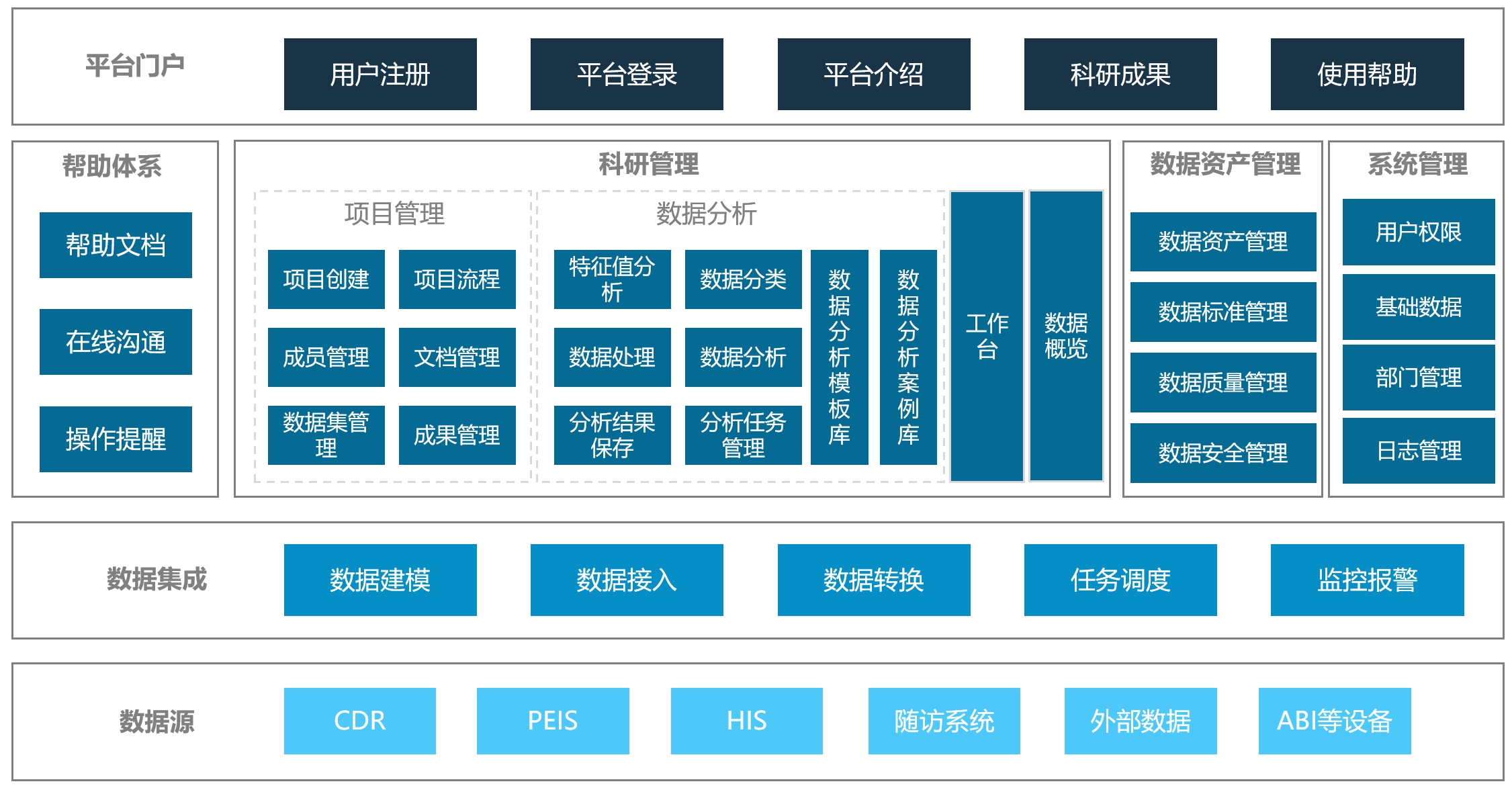
# 快速入门
# 概述
平台的功能主要包括以下几大部分:
- 工作台:个人的平台首页,可以概览用户的使用信息以及提供快捷入口。
- 数据概览:所有用户可使用,可以概览平台提供的数据的整体情况,方便用户可以快速判断申请的数据范围。
- 科研管理:对科研项目的生命周期进行管理,可以创建项目并申请立项,立项通过后可以使用项目过程的数据集、数据分析等服务。
- 平台管理:服务于平台的数据管理人员,可以实现查看平台的数据的整体情况、对数据进行管理、分配数据权限等操作,并对项目流程进行审批。
- 数据应用:可以直接使用的数据应用服务,目前提供了ABI数据的智能转换和体检数据的整体分析。
- 在线沟通:用户可以发表主题或进行提问和回复,在线进行快速沟通。
# 角色说明
平台提供用户管理和角色管理功能,可以灵活的为用户分配权限。为了方便对平台使用进行说明,把用户分为三类角色:
- 科研项目负责人:对项目全流程进行管理。
- 科研项目参与人:查看项目信息,使用数据探索、数据分析等功能完成科研任务。
- 科研管理人员:指科研管理人员、数据管理人员,对医疗科研的整体情况负责,在平台上负责流程审批、数据权限审批、项目检查等工作。
- 系统管理员:负责平台的运维工作,包括用户权限管理、基础数据管理、数据集成等系统运维工作。
# 核心流程
# 项目管理流程
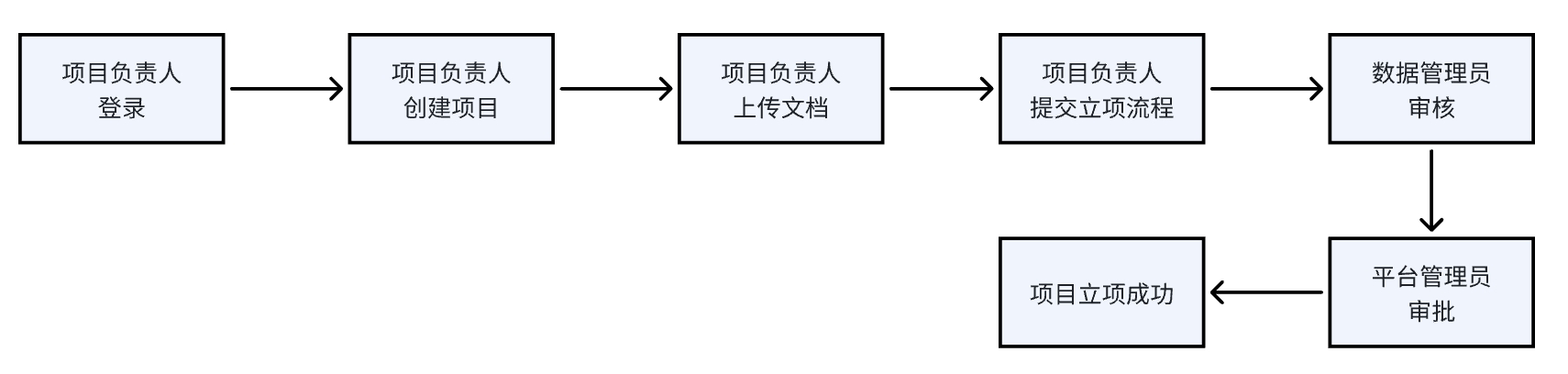
# 数据概览和数据权限申请
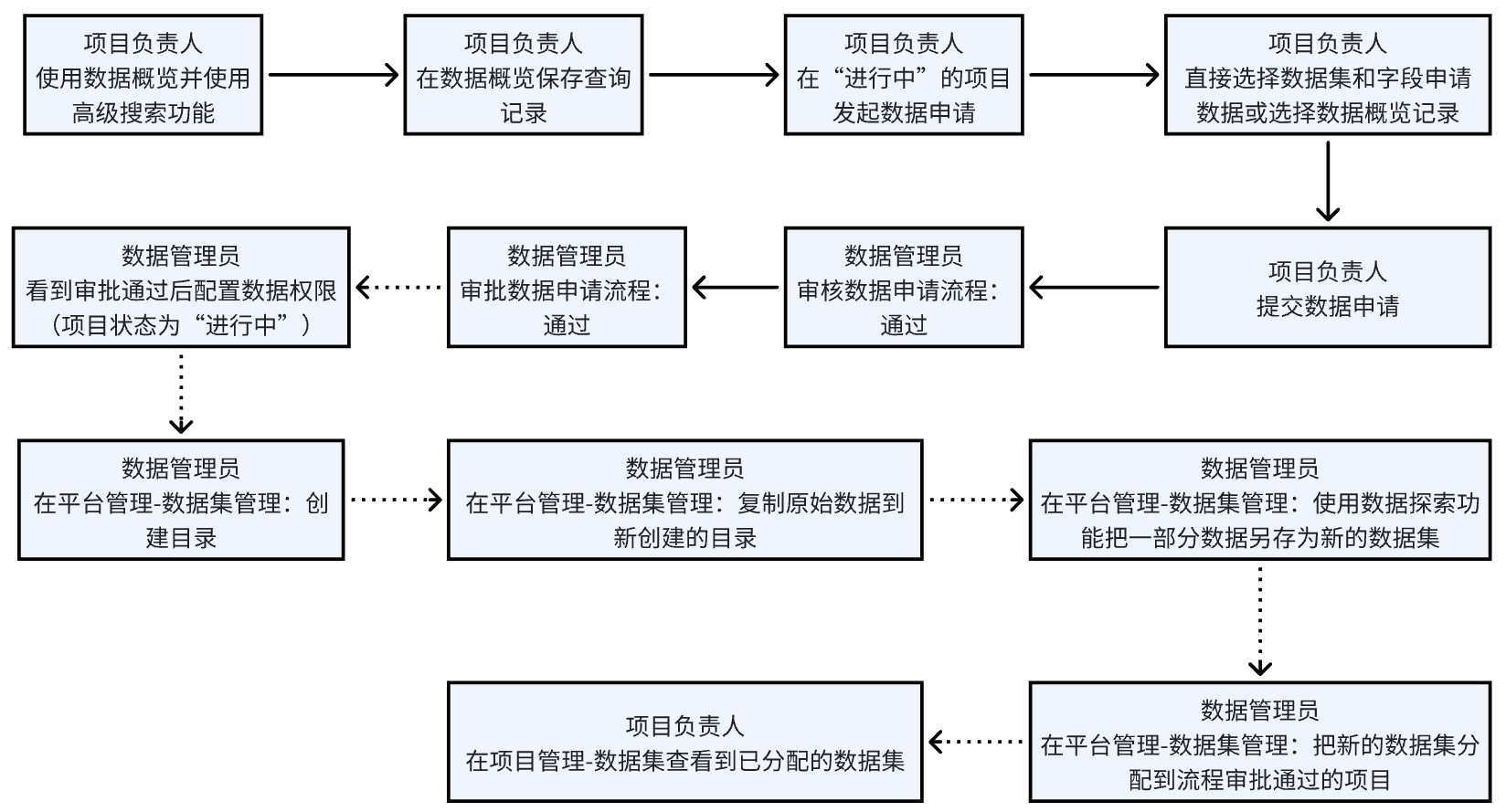
# 生成个人数据集并分析

# 工作台
- 使用角色:全部用户
- 功能简介:个人平台使用情况概览。
- 使用说明:
- 查看项目:展示用户负责的或者参与的未结项的项目列表,点击项目卡片可以快速跳转到项目视图。点击“全部项目”可以查看所有的项目列表。
- 快速开始/便捷导航:用户使用频率较高的操作可以通过快速导航进入。

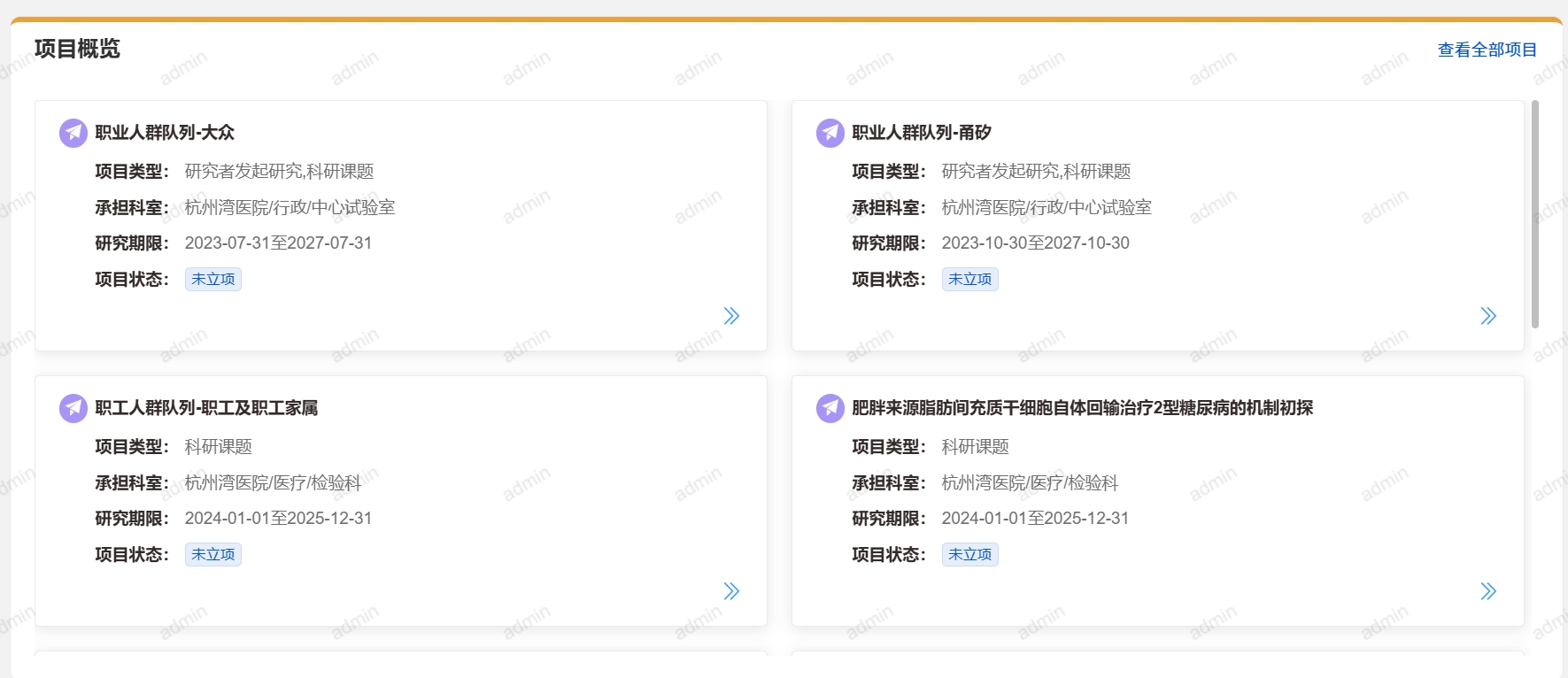
- 统计:对用户使用平台的数据资产数量进行统计,包括项目数量、项目成果数量、数据集数量等。
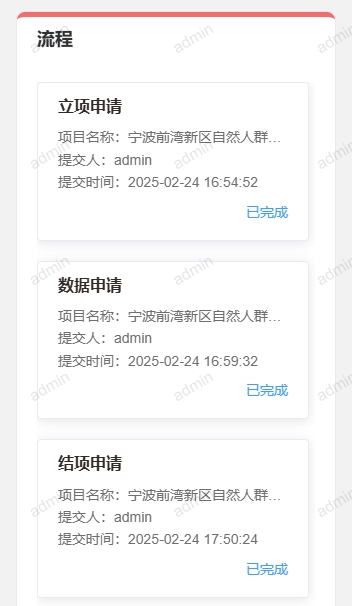
- 流程:查看当前进行中的流程的审批状态。
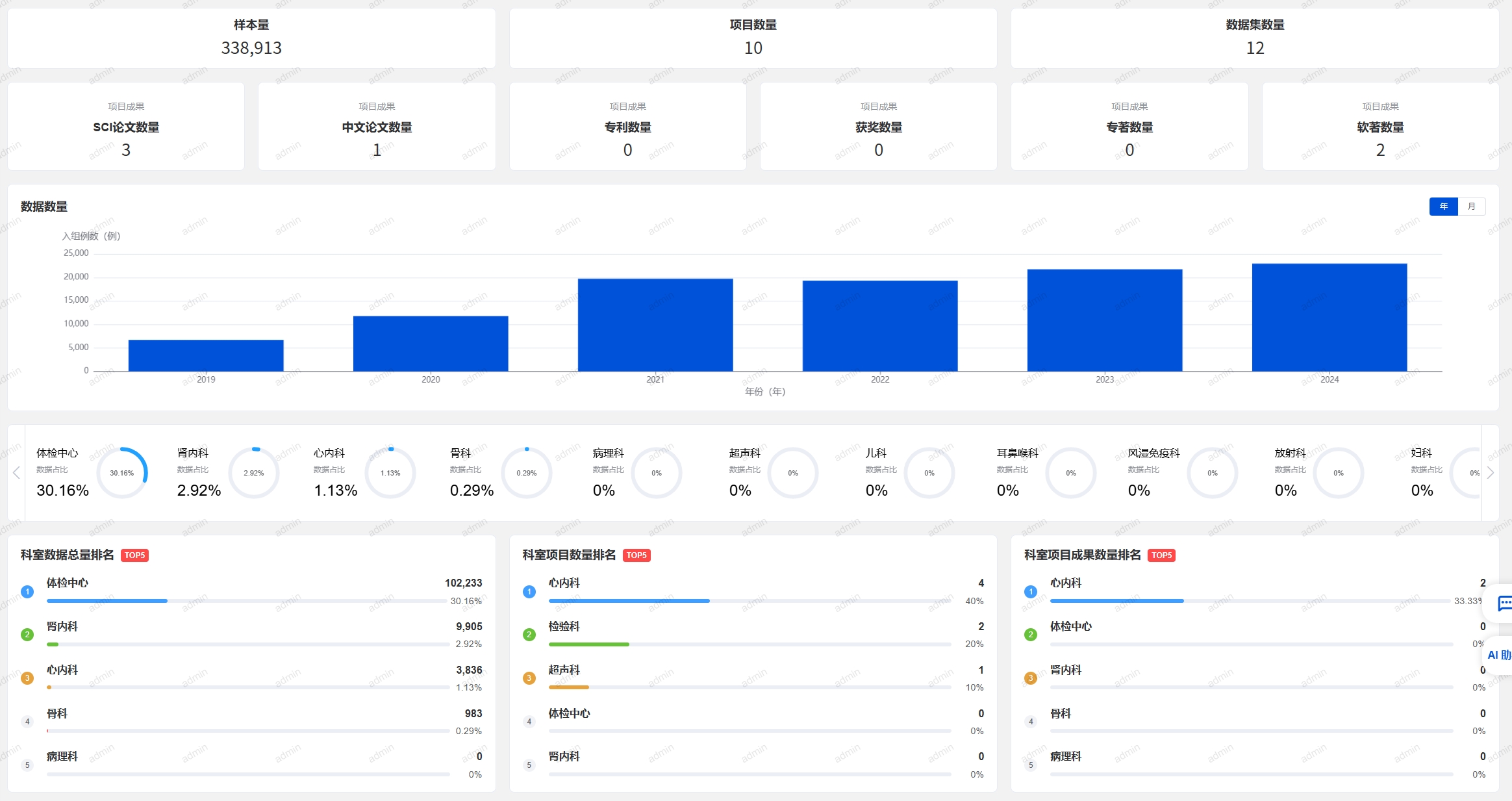
# 数据资产全景
- 使用角色:科研管理人员
- 功能简介:对平台整体的数据资产进行概览。
- 使用说明:
- 样本量:平台所有数据集的样本数量。
- 数据集数量:原始数据集的数量。
- 项目数量:已立项的项目数量。
- 项目成果数量:包括SCI论文数量、中文论文数量、专利数量、获奖数量、专著数量、软著数量。
- 数据数量日期趋势图:数据入库的变化趋势。
- 数据占比:各科室的数据数量占比。
- 科室总量排名:各科室的数据数量排名。
- 科室项目数量排名:各科室已立项的项目数量排名。
- 科室项目成果数量排名:各科室项目成果数量排名。
# 数据概览
- 使用角色:全部用户
- 功能简介:用户在项目立项申请或者申请数据权限之前可以通过该功能大致了解数据的情况,以判断数据是否满足科研要求。
- 使用说明:
- 概览记录:
- 查看列表:点击“数据概览”可以进入数据概览记录列表,可以查看以前的浏览记录。
- 继续浏览:在列表数据的后方点击“浏览”可以继续上次的浏览。
- 点击“浏览数据”可以进入数据概览页面。

数据概览:
- 选择数据集:在页面左上角可以选择要查看的数据集。
- 选择字段:在“可选字段”下选择要查看的字段,可以多选。
- 查看数据内容:选中字段后,可以在右侧查看数据的概括,包括数据的数量范围和非空值数据的数量范围,以及示例数据(不是全部数据)。
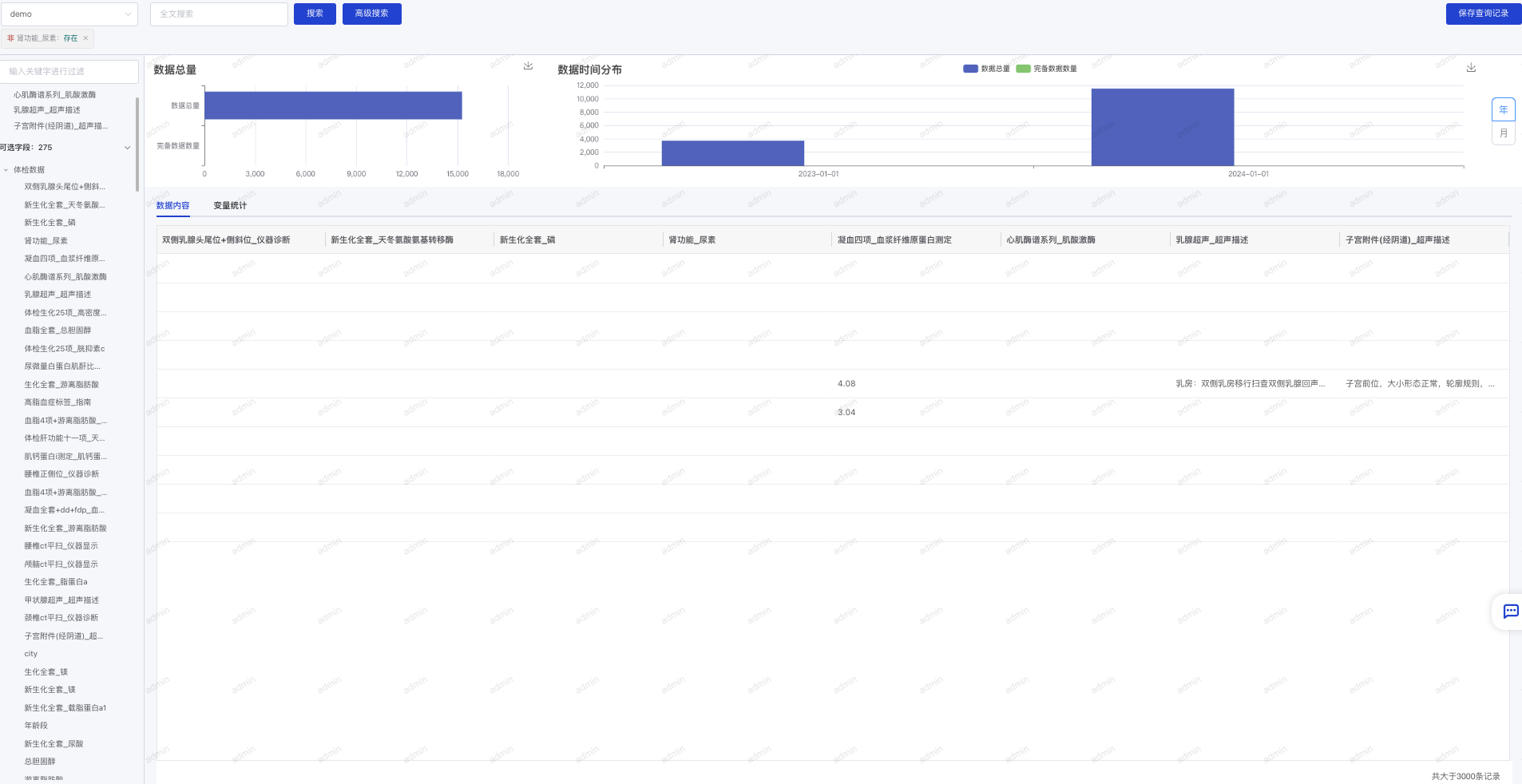
- 查看变量统计:选中字段后,在右侧数据展示区域点击“变量统计”,可以查看每个变量的统计概况。
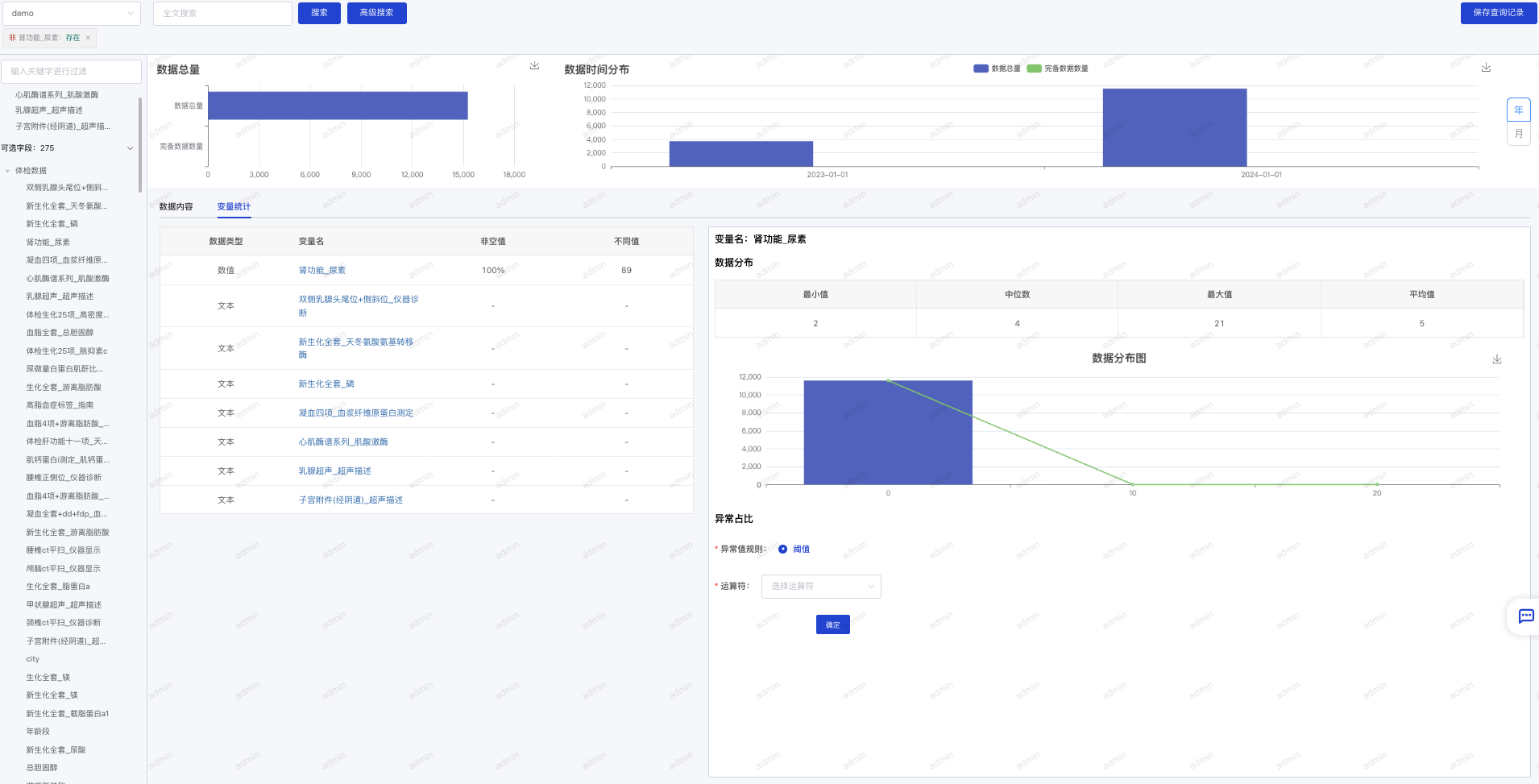
- 保存查询记录:在页面右上角,可以点击“保存查询记录”可以保存当前的查询条件,可以方便下次继续查看。
# 科研管理
[!NOTE]
项目在立项申请和数据权限申请通过后才能使用数据集、数据分析等功能。
# 创建项目
- 使用角色:全部用户
- 功能简介:用户需要开展科研活动时,首先要创建项目,然后进一步可以申请立项和数据权限。
- 使用说明:
- 项目列表:点击“项目管理”可以进入项目列表页面,可以查看当前管理或参与的项目。

创建项目:点击“新增”按钮可以弹出项目创建页面,填写相关信息并保存后可以创建项目,创建的项目默认为“未立项”状态。
删除项目:状态为”未立项“的项目可以执行删除操作。
修改项目基本信息:项目管理人员可以修改项目基本信息,在列表页点击“修改”按钮进行修改。
# 项目立项
- 使用角色:科研人员/科研管理人员
- 功能简介:项目创建后,需要项目立项成功后才能使用项目管理的全部功能。
- 使用说明:
- 在“项目视图-流程”页面,点击“立项流程”按钮发起立项流程,弹出立项流程发起页面。
- 在立项流程发起页面,包括两大部分内容:项目信息和附件。项目信息如需修改需要在概览页或者项目列表页点击编辑按钮修改。附件只能选择已上传到平台的项目附件,需要在“项目视图-文档”功能进行维护。
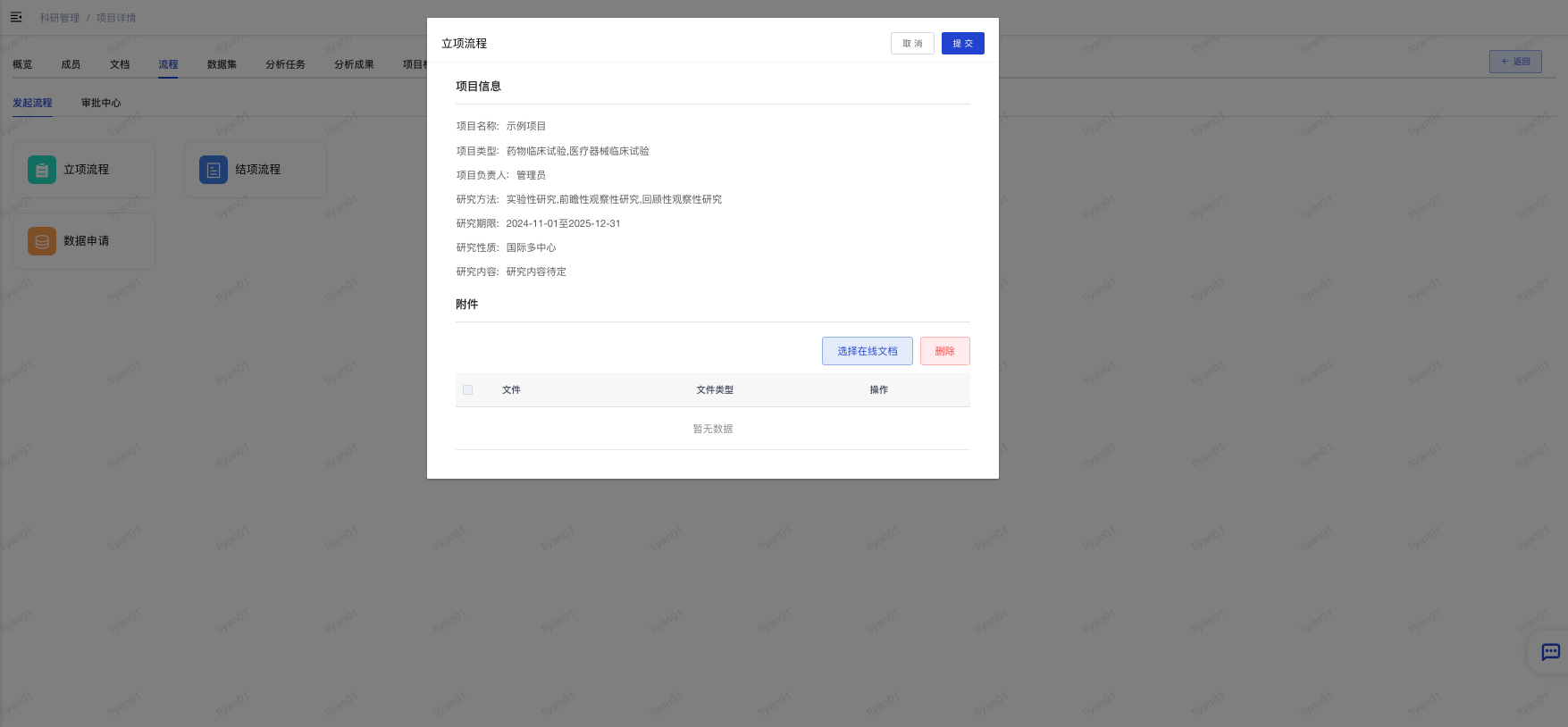
- 在立项流程发起页面,点击“取消”可以取消当前操作,点击“提交”则正式提交立项申请。立项申请由科研管理人员进行审批。
- 项目成员可以在“项目视图-流程-审批中心”查看已提交的立项流程的审批状态。
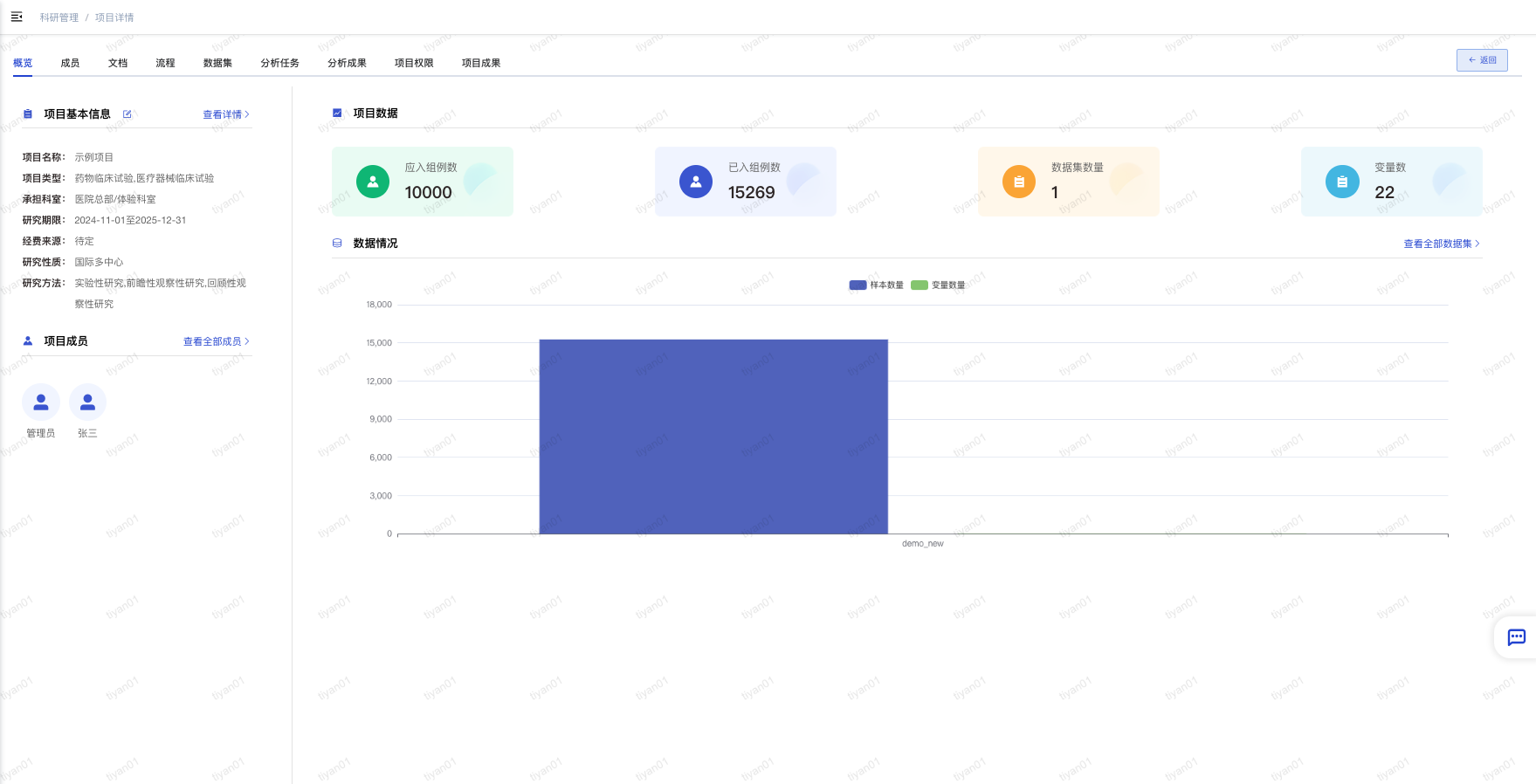
# 项目概览
- 使用角色:所有项目成员
- 功能简介:浏览项目信息和数据情况。
- 使用说明:
- 在“项目视图-概览”页面,可以查看项目的整体情况。
- 项目基本信息:可以查看项目关键信息并进行编辑,也可以点击“查看详情“查看项目全部基本信息。
- 项目成员:查看项目主要成员列表,也可以点击”查看全部成员“进入项目成员管理列表进行查看和管理。
- 项目数据:项目关键数据,包括应入组例数、已入组例数、数据集数量、变量数量。
- 数据情况:查看项目所有数据集的数据统计,包括样本数量和变量数量。
# 成员管理
[!NOTE]
成员管理只做项目成员的基本信息管理,与项目权限无关。
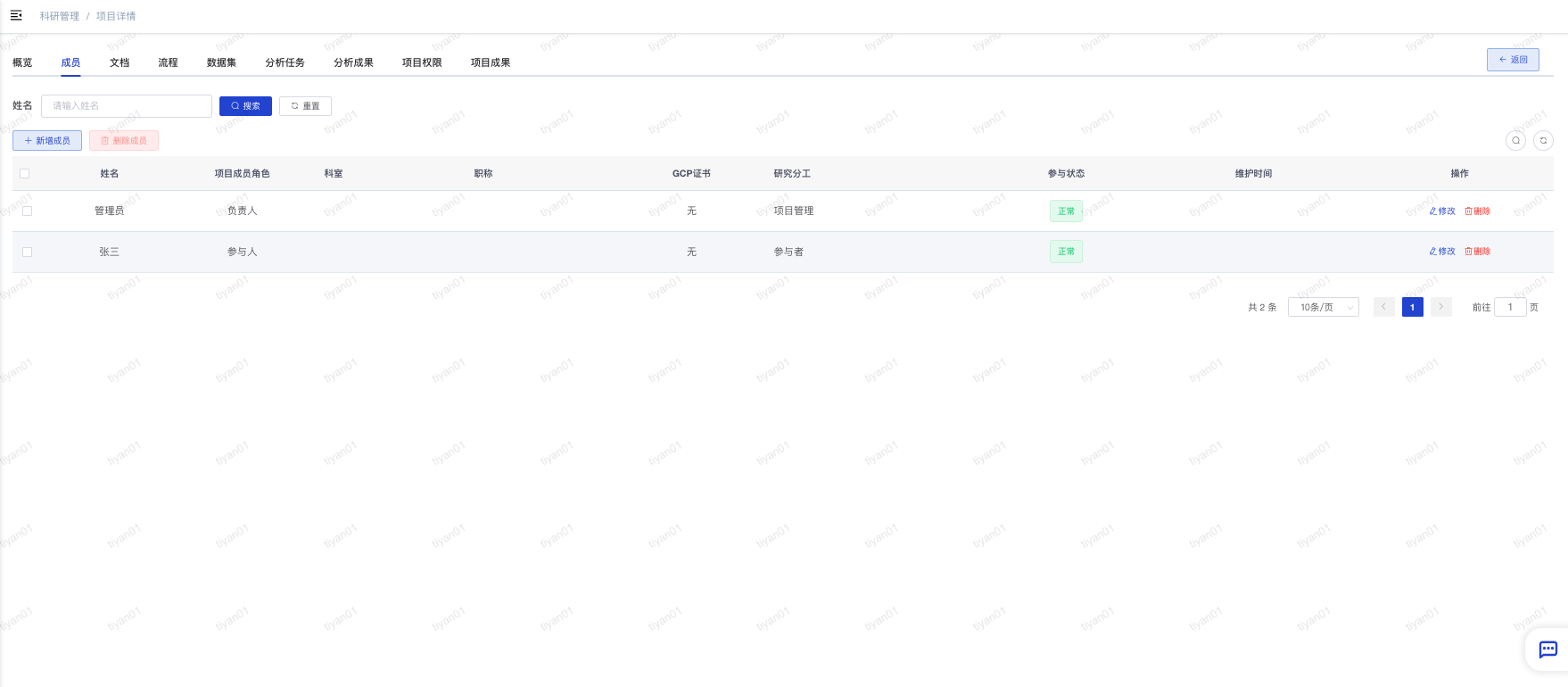
- 使用角色:科研项目负责人
- 功能简介:对参与项目的人员基本信息进行管理。
- 使用说明:
- 成员列表:在“项目视图-成员”页面可以查看项目成员列表。
- 新增成员:点击“新增成员”弹出成员编辑页面,可以增加新的项目成员,注意项目成员有“负责人”和“参与人”两种角色。
- 修改和删除:在列表页面可以点击“修改”按钮修改成员信息,点击“删除”按钮可以删除当前成员。注意:虽然平台没有对成员数量进行限制,但原则上要至少有一个“负责人”。
# 文档管理
[!NOTE]
在文档管理上传文档后,项目立项和项目结项流程才能选择在线文档。
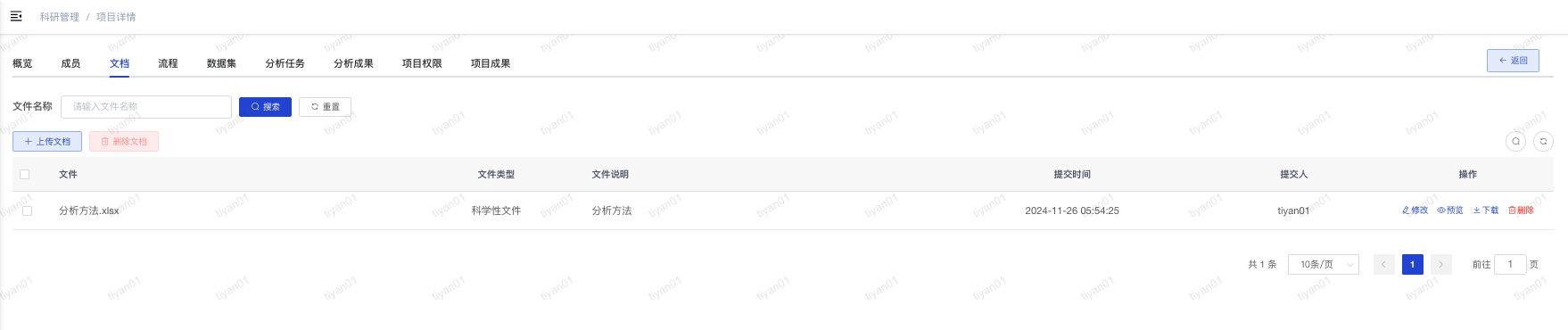
- 使用角色:科研项目负责人和参与人
- 功能简介:对项目相关的文档进行管理(如立项需要的文档)
- 使用说明:
- 文档列表:点击“项目视图-文档”可以查看已上传的文档列表。
- 修改操作:可以修改文件类型、文件说明。
- 预览:支持常见格式的在线预览。
- 下载:下载文档到本地。
- 删除:删除当前文档。
- 上传文档:点击“上传文档”按钮弹出文档上传页面,可以将本地的文档上传到平台。注意:文档类型包括科学性文件和伦理性文件。
# 流程管理
- 使用角色:科研项目负责人
- 功能简介:发起项目相关的立项、数据申请、结项流程。
- 使用说明:
- 项目立项:查看“项目立项”功能介绍中的详细说明。
- 结项流程:状态为“进行中”的项目才能发起结项流程。项目结项的操作和立项类似。
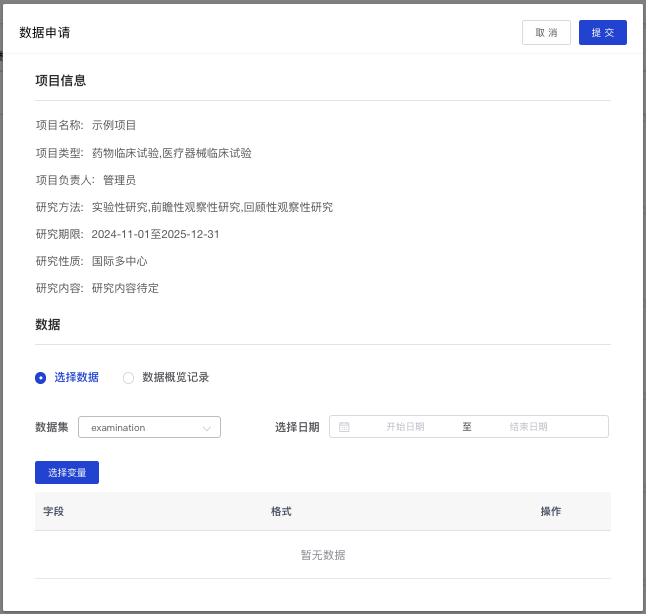
- 数据申请:项目立项后需要申请数据已开展科研工作,点击“数据申请“弹出数据申请页面。选择数据范围的方式有两种:
- 直接选择数据:选择数据集、数据日期范围、变量。
- 根据数据概览记录选择:可以直接选择在”数据概览“里的查询记录,作为数据申请的条件范围。
- 在数据申请流程发起页面,点击“取消”可以取消当前操作,点击“提交”则正式提交数据申请。数据申请由科研管理人员进行审批。
- 项目成员可以在“项目视图-流程-审批中心”查看已提交的数据申请流程的审批状态。
# 数据集管理
[!NOTE]
项目立项成功,并且项目数据申请流程通过后,管理员根据申请进行数据集权限分配,项目成员就可以在数据集列表查看数据集并进行数据探索、数据分析任务。
- 使用角色:所有项目成员
- 功能简介:对项目数据集进行管理,是数据探索和数据分析的入口。
- 使用说明:
- 数据集列表:点击“项目视图-数据集”,可以进入数据集列表页面。
- 项目数据集:数据集类型为“项目”的数据集,是项目的初始数据集,由科研管理人员进行数据权限分配后形成的数据集,项目成员无法删除。项目成员可以基于初始数据集创建个人数据集。
- 复制操作:在项目列表可以点击“复制”按钮进行数据集复制操作,重命名后形成新的数据集。
- 删除操作:用户可以删除自己创建的数据集类型为”个人“的数据集。
- 数据探索和数据分析功能在下面详细展开介绍。

# 数据探索
[!NOTE]
平台原则上不允许对数据进行直接修改,只能通过新增变量(列)、添加标签的方式增加需要的数据。
- 使用角色:所有项目成员
- 功能简介:查看数据集的数据情况并进行数据处理。
- 使用说明:
- 进入方式:在“项目视图-数据集”数据集列表后点击“数据探索”进入数据探索页面。
- 选择数据集:默认数据集是在列表页选择的数据集,也可以在左上角切换数据集。
- 选择查看的字段:“已选字段”是已选中并在右侧展示的变量,如需新增变量,可以在“可选字段”列表点击字段右侧的加号进行选择。
- 查看数据总量和完备数据数量:数据总量既数据总行数,完备数据指所有变量都有数据的数量。
- 数据内容:展示已选变量的数据内容。
- 变量统计:查看已选变量的数据质量情况,包括非空值、不同值、数据分布。
- 保存已选数据:将当前选择的数据另存为新的数据集。
- 快速进入数据分析页:可以点击右上角的“数据分析”页面进入数据分析页面。

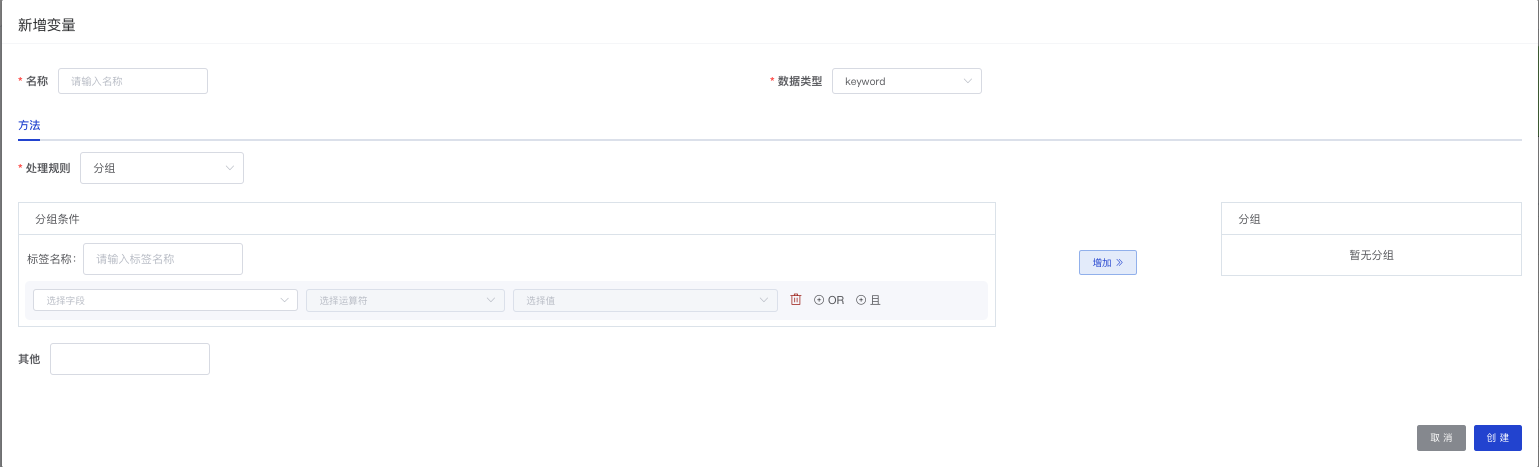
- 新增变量:目前平台只支持分组操作。在数据探索页面点击“新增变量”弹出编辑页面。
- 填写新的变量名称和数据类型。
- 选择处理规则:目前只支持“分组”。选择完处理规则后,下方会弹出条件设置页面。
- 分组条件:选择标签生成的条件,可以根据多个变量条件。如:“性别”等于“男”。
- 标签名称:新的变量的数值,如:把原有的性别为“男”的数据设置标签名称为“1”。
- 点击’添加“后,右侧是已设置完成的分组条件。
- 可以通过”其他“功能为未设置规则的变量统一设定规则。
- 点击”创建“按钮后,新的变量被创建,可以在数据探索左侧变量列表进行查看。
# 数据分析
- 使用角色:所有项目成员
- 功能简介:对数据进行图表可视化分析或算法分析。
- 使用说明:
- 进入方式:在“项目视图-数据集”数据集列表后点击“数据分析”进入数据分析页面。
- 数据分析页面包括三个区域:数据集和变量选择区域、图表和算法设置区域、分析结果展示区域。
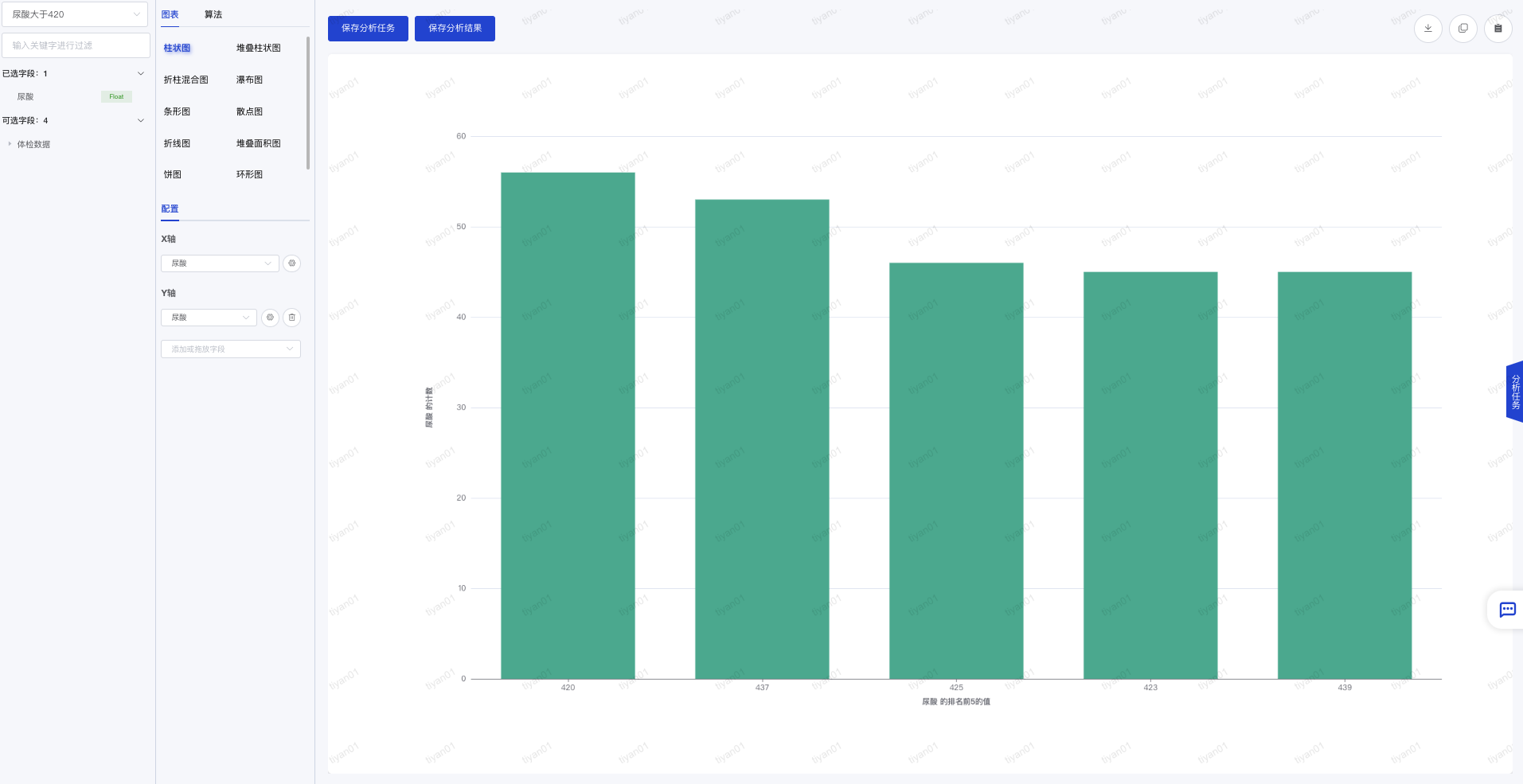
- 选择数据集:在左上角可以切换数据集。可选的数据集是当前项目下的项目数据集或用户的个人数据集。
- 选择图表或算法:选择图表或算法后,下方会有图表和算法对应的配置要求。
- 查看分析结果:图表或算法的配置完成后,右侧会呈现分析结果。
- 保存分析任务:点击“保存分析任务”后可以保存当前的分析任务,下次可以继续分析任务。
- 保存分析结果:可以把当前的图表结果或算法结果进行保存,可以在“分析成果”里查看。
- 查看分析任务:点击页面右侧的“分析任务”按钮,可以查看已保存的分析任务列表并继续进行分析。
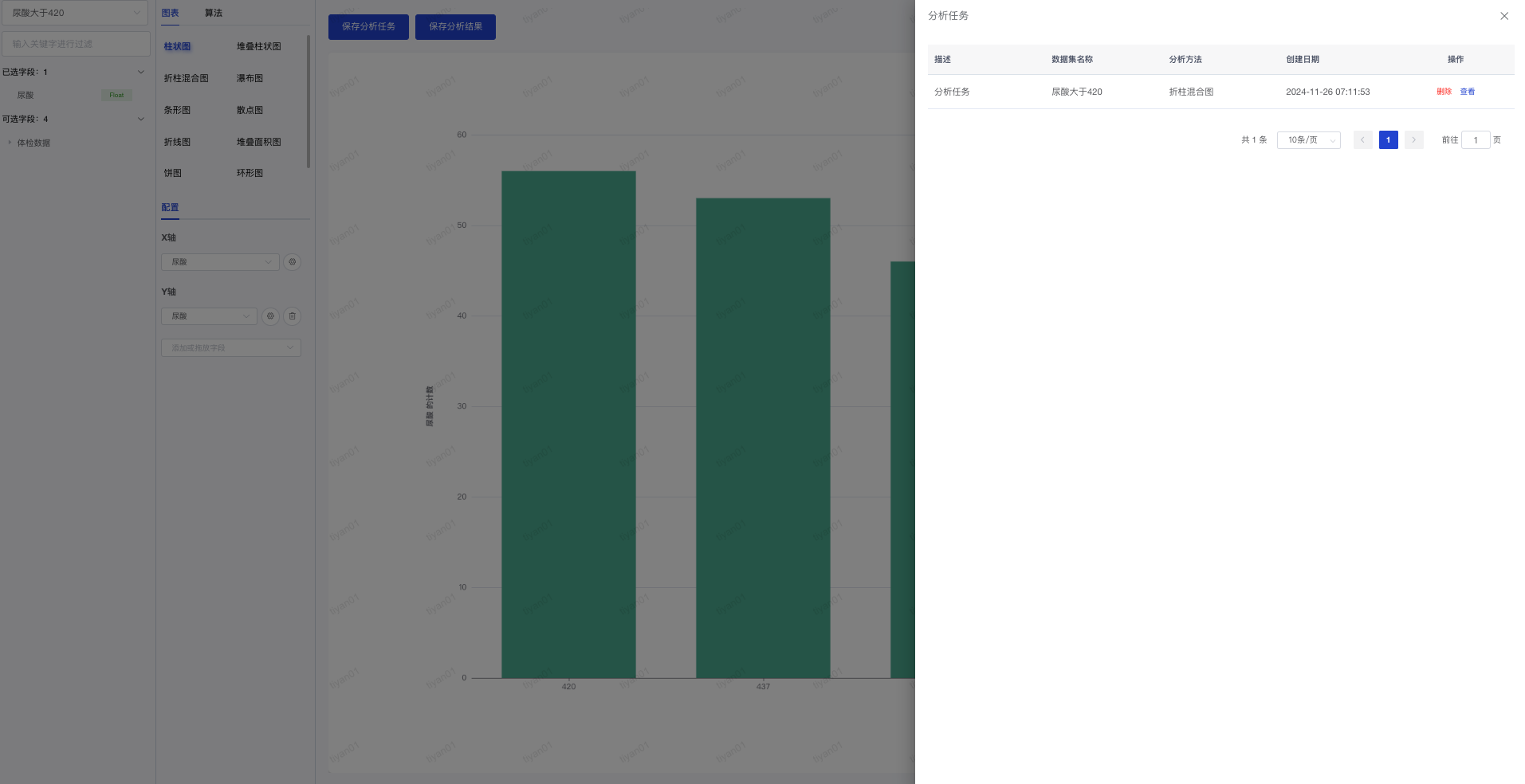
# 分析任务管理
- 使用角色:所有项目成员
- 功能简介:查看已保存的分析任务,可以继续进行分析。
- 使用说明:
- 点击“项目视图-分析任务”进入分析任务列表。
- 在列表页面点击“查看”,可以进入数据分析页面查看分析任务的情况继续进行分析。
- 在列表页面点击“删除”,可以删除分析任务。

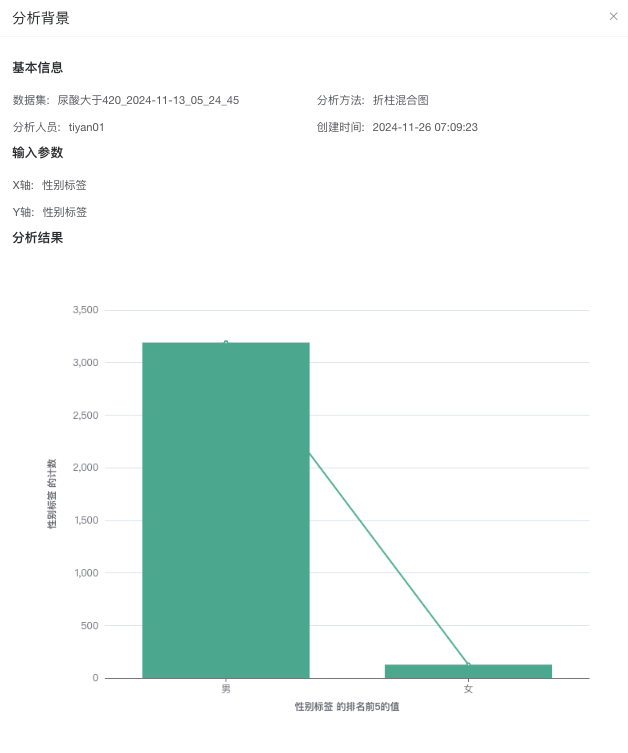
# 分析成果
- 使用角色:所有项目成员
- 功能简介:查看已保存的分析成果。
- 使用说明:
- 点击“项目视图-分析成果”进入分析成果列表。
- 在列表页面点击“查看”,弹出分析成果页面。
- 在列表页面点击“删除”,可以删除分析成果。
# 项目权限
- 使用角色:项目管理员
- 功能简介:对项目用户的权限进行分配
- 使用说明:
- 点击“项目视图-项目权限”进入项目用户列表。
- 项目创建后默认创建用户为“管理员”。
- 转移管理员权限:创建人可以通过该功能把管理员权限转移给其他用户。
- 新增项目权限:点击”新增项目权限“弹出编辑页面,项目权限包括两种类型:维护人和普通用户。
- 维护人:拥有所有项目权限,可以编辑项目基本信息、发起流程、管理项目成员、管理项目权限。
- 普通用户:可以使用数据集、数据探索、数据分析、分析任务管理、分析成果管理、文档管理的所有功能,但不能修改项目信息、发起流程、修改项目权限。
# 项目成果
- 使用角色:项目管理员
- 功能简介:管理项目成果。
- 使用说明:
点击“项目视图-项目成果”进入项目成果列表。
点击“新增”,选择项目成果类型,进入成果新增页面。不同的项目成果管理的内容不同。

# 平台管理
# 原始数据
- 使用角色:科研管理人员
- 功能简介:从各个系统经过ETL后加载到平台的初始数据集。
- 使用说明:
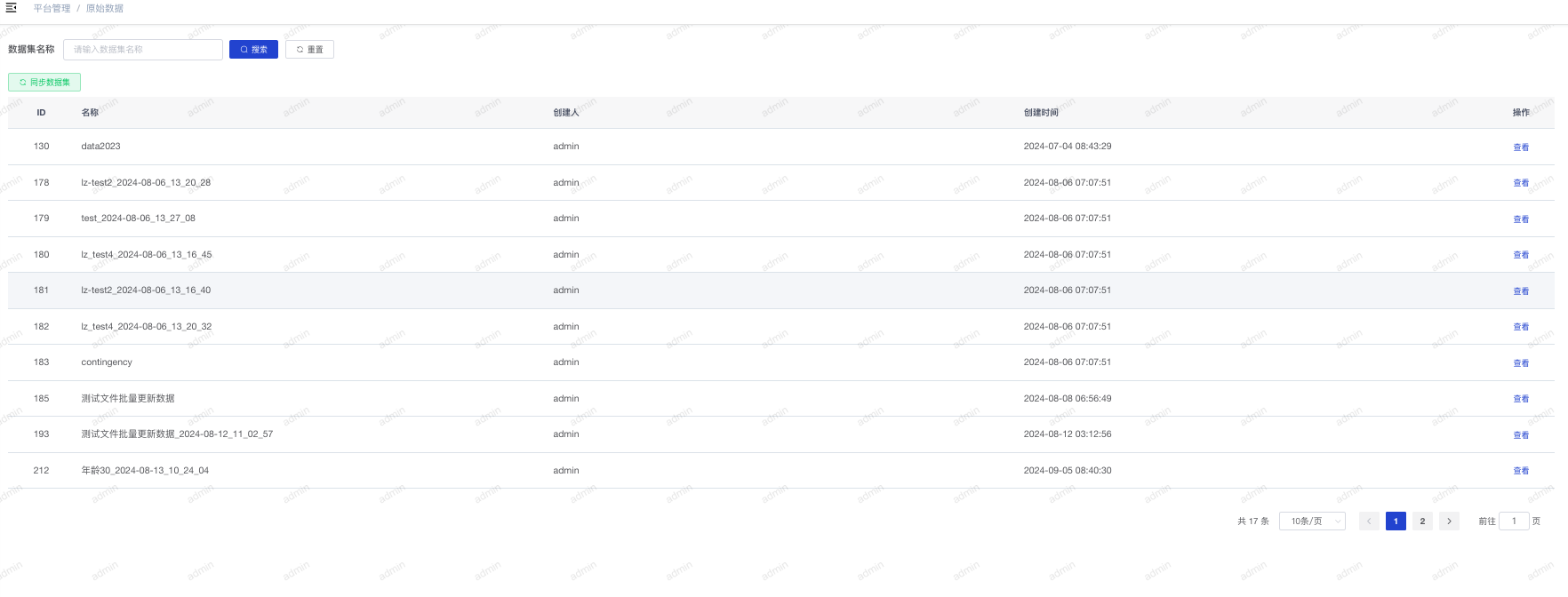
- 点击“平台管理-原始数据”进入原始数据集列表,可以查看目前平台已经存在的原始数据集。
- 点击“同步数据集”可以进行刷新。
- 点击列表后的“查看”,可以查看数据集的数据内容和数据结构。
# 数据集管理
[!NOTE]
数据集管理中基于原始数据创建数据集后,新的数据集只包含复制时的数据,不随原始数据集更新。
- 使用角色:科研管理人员
- 功能简介:项目数据集原始数据集进行创建,在数据集管理里,对数据集进行组织和权限分配,并可以进行数据补充等操作。
- 使用说明:
- 数据集列表:点击“平台管理-数据集管理”进入到数据集列表页。左侧为数据目录,右侧为数据集列表。
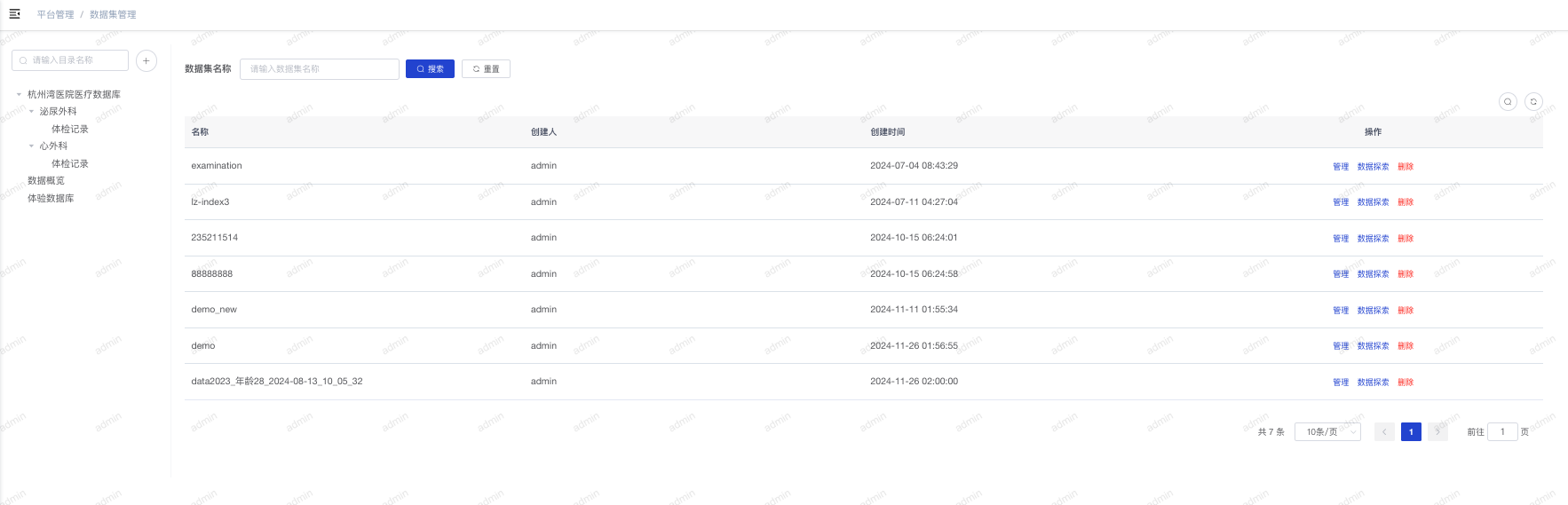
- 创建目录:点击目录树右上角的加号按钮,选择“创建目录”可以新增目录。
- 基于原始数据创建数据集:点击目录树右上角的加号按钮,选择“添加原始数据”可以复制原始数据到分析数据集。
- 基于现有数据集创建新的数据集:点击数据集列表右侧的“数据探索”,在数据探索页面,可以选择数据集并进行筛选,将筛选结果保存为新的数据集。
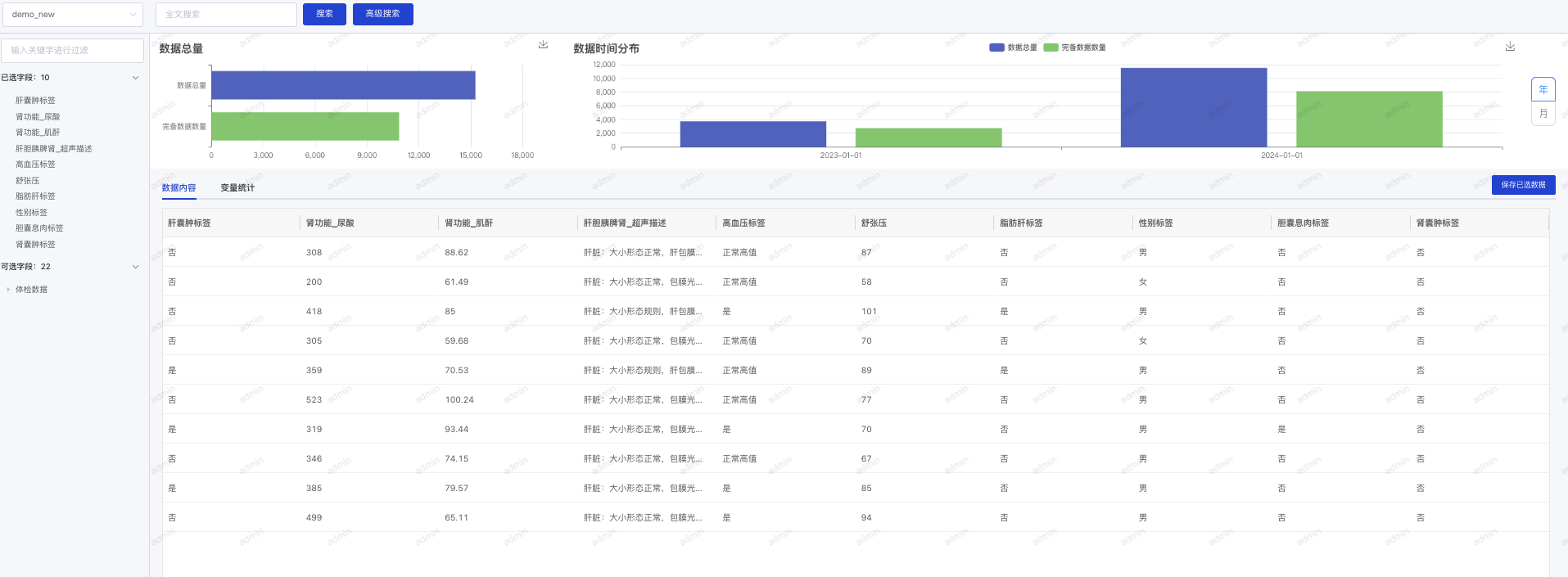
- 查看数据内容:在数据集管理页面可以查看数据集的数据内容。
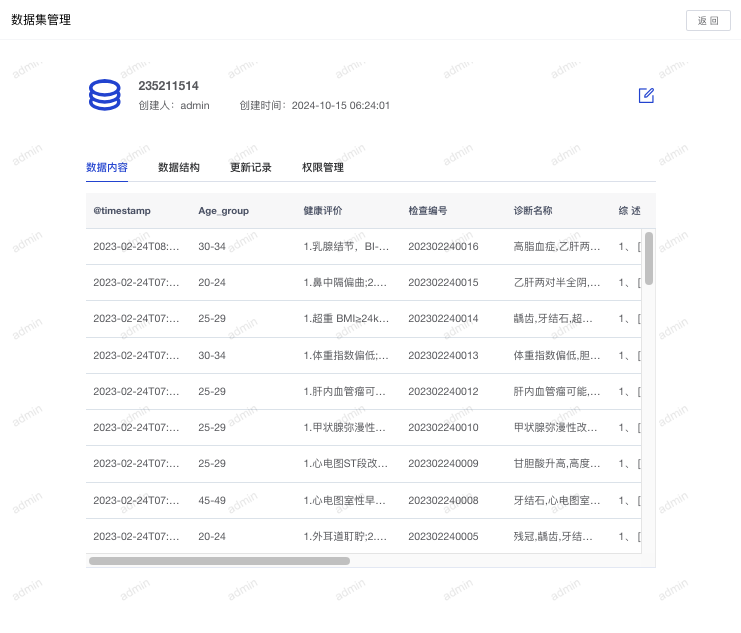
查看数据结构:在数据集管理页面点击“数据结构”可以查看数据集的变量及数据类型,并可以对变量进行分组,方便在数据探索和数据分析时进行数据展示。
![平台管理-数据集管理c]()
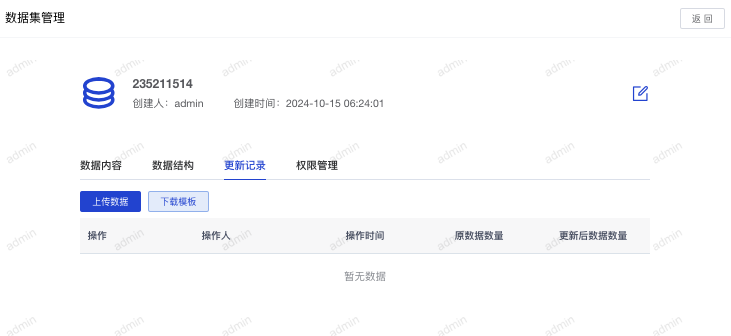
查看数据集更新记录:在数据集管理页面点击“更新记录”可以查看数据集的数据更新情况,也可以通过下载模板-上传数据的方式导入外部数据。
![平台管理-数据集管理d]()
权限管理:数据集的项目权限分配,可以通过点击“新增项目”按钮分配数据集的项目权限。


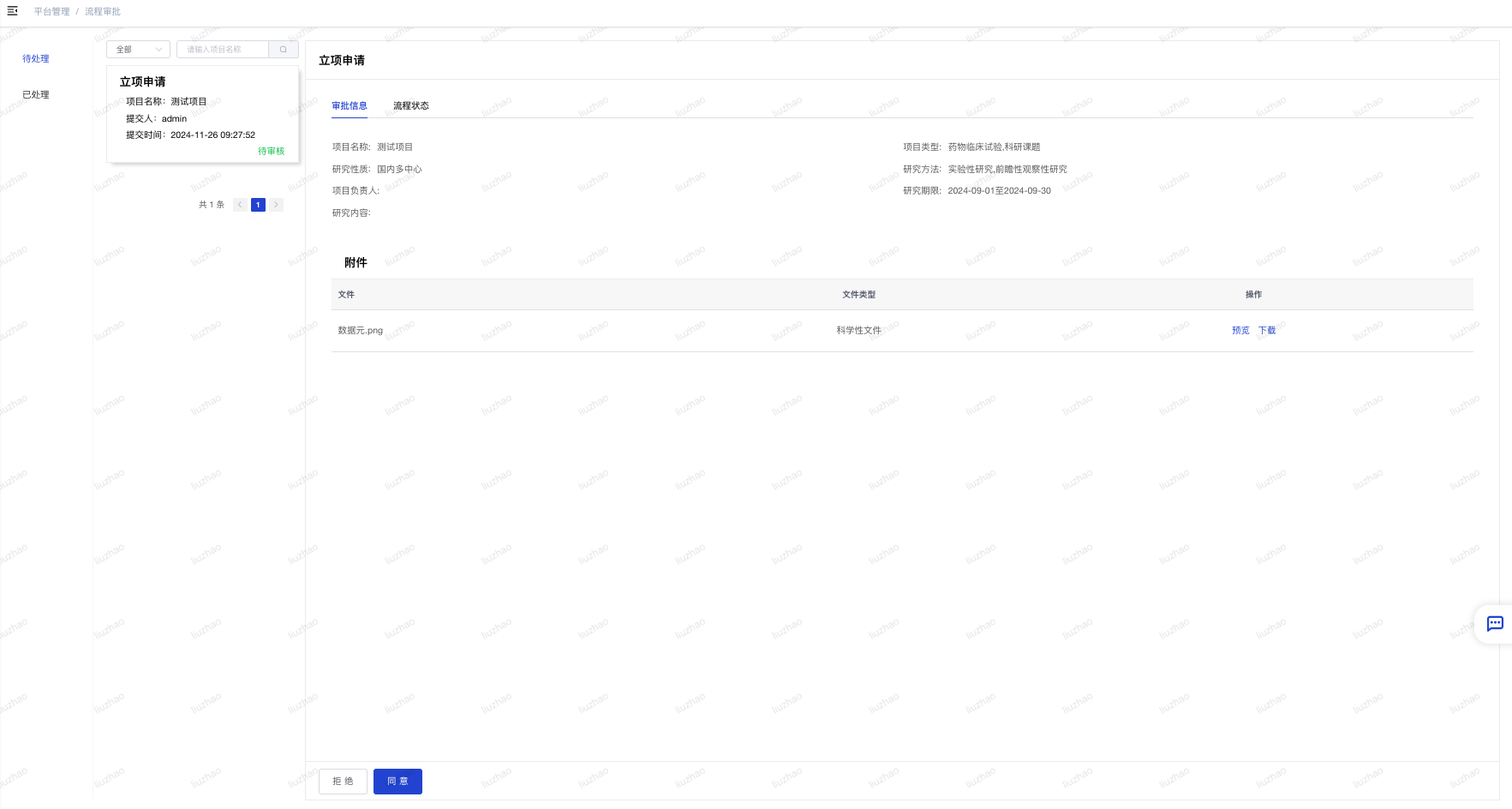
# 流程审批
- 使用角色:科研管理人员
- 功能简介:对项目负责人提交的流程进行审批。
- 使用说明:
- 点击“平台管理-流程审批”进入流程管理列表。
- “待处理”显示的是未审批的流程,“已处理”显示的是已审批完成的流程。
- 在“待处理”的流程列表里,点击项目卡片可以查看审批信息详情,点击下方的“同意”或“拒绝”按钮进行审批
# 数据应用
# ABI数据导入
- 使用角色:负责ABI数据入库的用户
- 功能简介:对ABI设备的PDF文件转换为结构化数据。
- 使用说明:
- 数据列表:点击“数据应用-ABI数据导入”进入ABI数据列表页面。
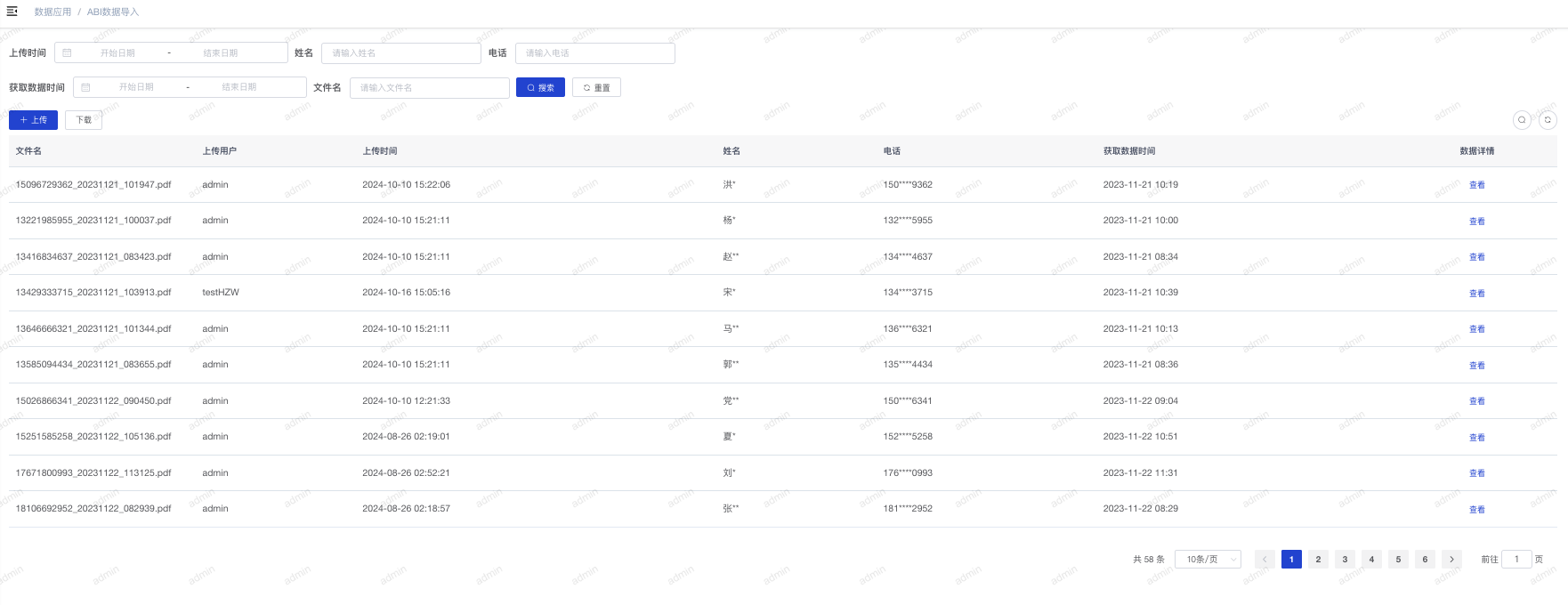
- 批量上传PDF文件:批量选择或拖动PDF文件到上传框,实现文件自动转换为数据。上传完成后数据列表刷新。
- 查看数据详情:在数据列表页,点击”查看“可以查看数据详情。

# 体检数据分析
- 使用角色:有体检数据查看权限的用户
- 功能简介:体检数据的统计分析
- 使用说明:
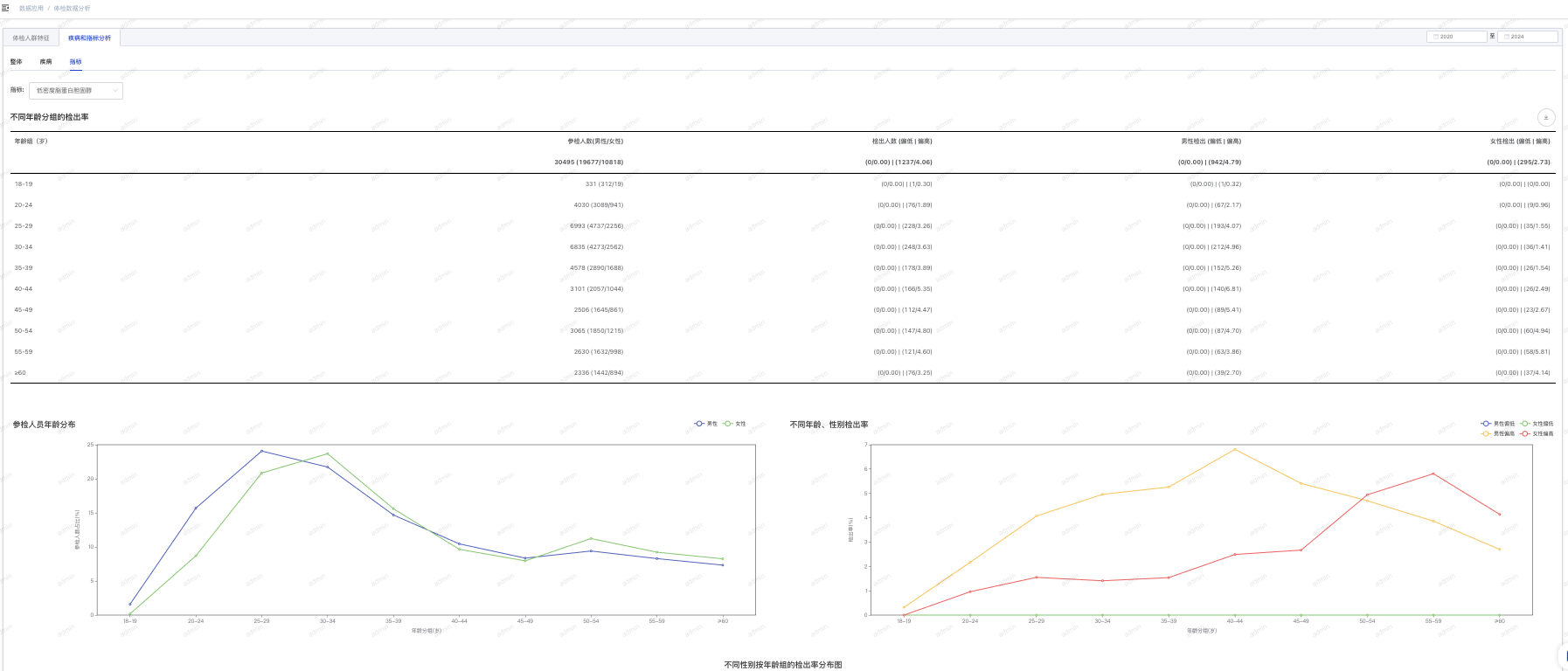
- 点击“数据应用-体检数据分析”进入体检数据统计分析页面。
- 选择年份,如2024,分析结果进行刷新。
- 体检人群特征:指体检人群的性别、年龄、地域、职业分布的分析。
- 疾病和指标分析:
- 疾病分析:选择疾病,如胆囊结石,可以查看基于该种疾病的年龄段、性别等多位维度的参检和检出率的分析。
- 指标分析:选择指标,如甘油三酯,可以查看该指标的异常分析(偏高、偏低)。
# 企业体检报告
- 使用角色:有企业体检数据查看权限的用户
- 功能简介:按企业查看体检数据的统计分析
- 使用说明:
- 点击“数据应用-企业体检报告”进入体检数据统计分析页面。
- 选择年份,如2024,分析结果进行刷新。
- 体检人群特征:指企业体检人群的性别、年龄等的分析。
- 疾病和指标分析:
- 疾病分析:选择疾病,如胆囊结石,可以查看基于该种疾病的年龄段、性别等多位维度的参检和检出率的分析。
- 指标分析:选择指标,如甘油三酯,可以查看该指标的异常分析(偏高、偏低)。
# 数据查询条件说明
在数据概览、数据探索功能中会使用相应的
| 中文运算符 | 用途说明 |
|---|---|
| 等于 | 用于精准查询,筛选等于某个指定内容的字段,例如:在性别中查询指定字符“男”,则查询结果中显示所有性别为“男”的数据。 |
| 不等于 | 用于精准查询,筛选不等于某个指定内容的字段,例如:在年龄中查询指定字符“29”,则查询结果中显年龄不等于29的其余所有数据。 |
| 包含 | 字段中包含该指定内容的所有数值,例如:在出生地_省中查询指定字符“河”,则查询结果中显示“河北省”和“河南省”的所有数据。 |
| 不包含 | 字段中不包含指定内容的所有数值。 |
| 属于 | 适用于指定非数值型字符的多条件筛选,例如:查询“行业”,可在选择框中选择多个行业名称,即可筛查所有制定行业内的所有数据。 |
| 不属于 | 适用于制定非数值型字符的多条件筛选,例如:查询“行业”,可在选择框中选择多个行业名称,即可筛查所有不在制定行业内的所有数据。 |
| 介于 | 值在两个值之间(含),如:年龄介于18-50,即18≤年龄<50。 |
| 不介于 | 值不在两个值之间(不含),如:年龄不介于18-50,即年龄≤18或者年龄<50。 |
| 空值 | 用于筛选指定端没有数值的字段,即空字段。 |
| 非空值 | 用于筛选指定端有数值(包括数值和文本)的字段,即非空字段。 |
# 图表说明
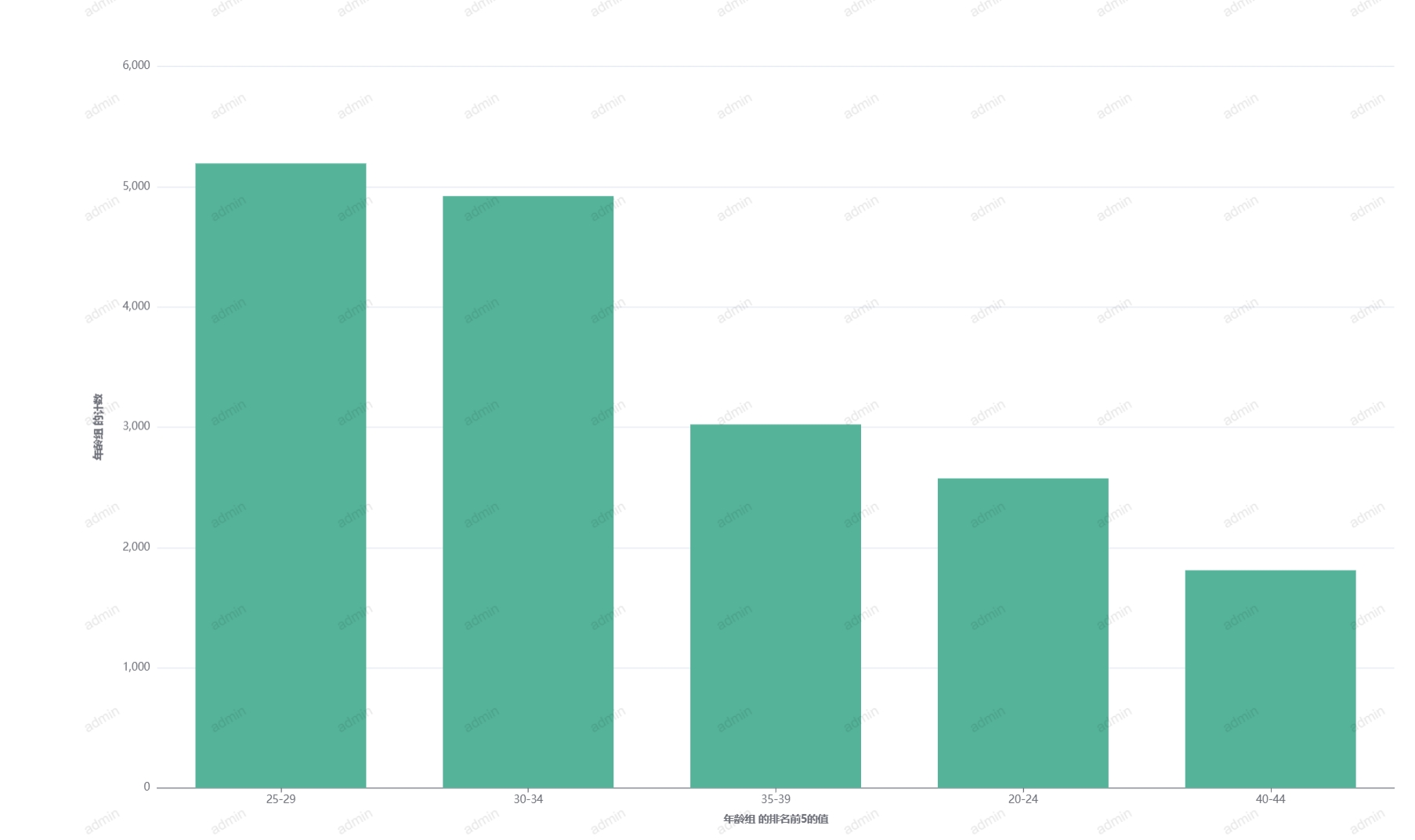
# 柱状图
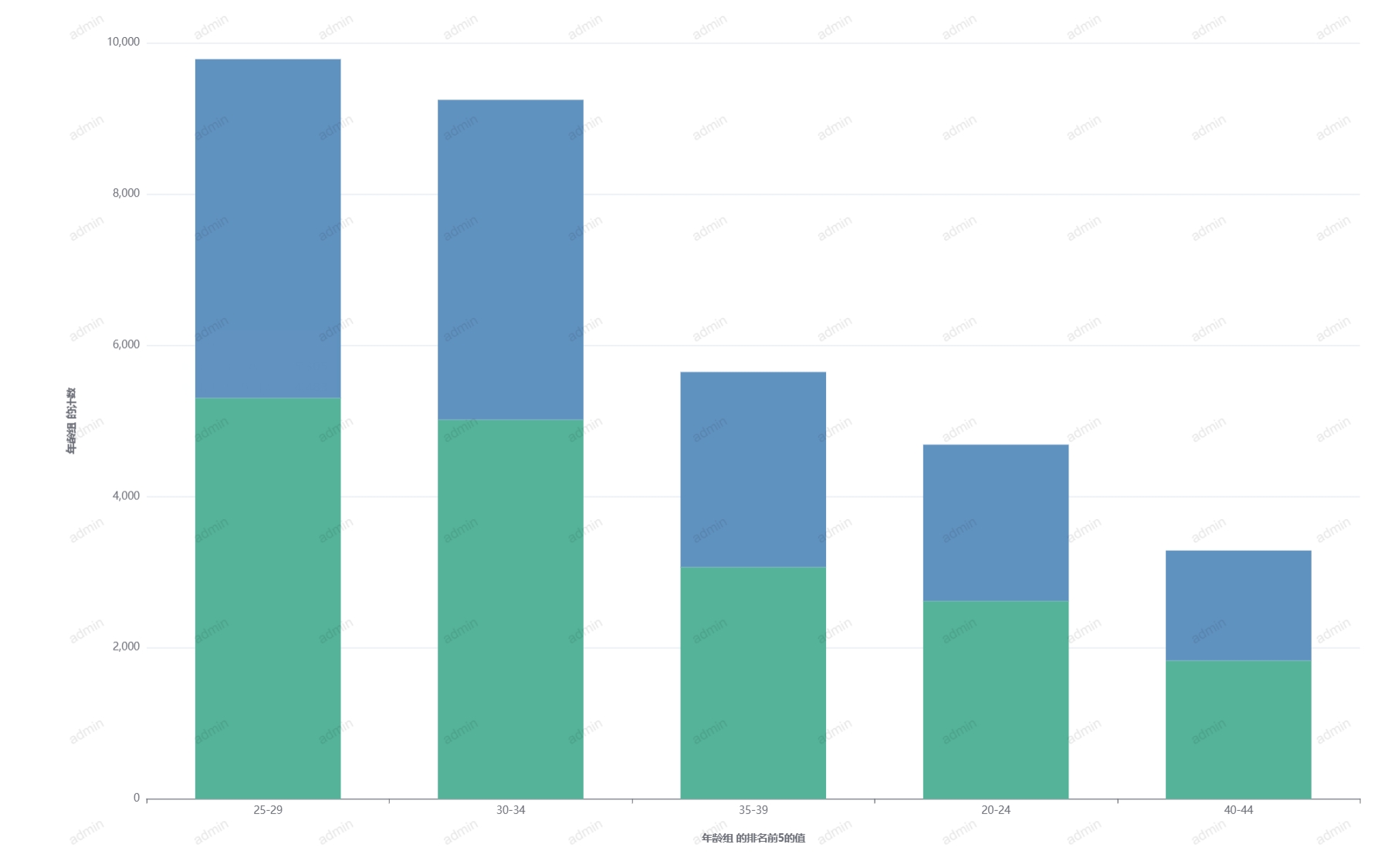
能够直观地展示不同类别之间的数值差异、时间序列数据的变化趋势、数据的频率分布等。通过合理选择柱状图的类型(如简单柱状图、堆叠柱状图等),可以更有效地传达数据信息,帮助观众快速理解数据的关键点。
# 柱状图
# 堆叠柱状图
# 折柱混合图
# 瀑布图
# 条形图
# 散点图
散点图(Scatter Plot)是一种用于展示两个变量之间关系的图表,它通过在二维平面上绘制数据点来直观地呈现变量之间的分布和相互关系。
# 散点图
# 气泡图
# 折线图
折线图能够直观地展示数据随时间或其他连续变量的变化趋势,帮助用户快速识别数据中的关键信息。
# 折线图
# 堆叠面积图
# 平滑折线图
# 阶梯折线图
# 堆叠折线图
# 面积图
# 饼图
饼图适用于展示部分与整体的关系、比较不同类别的比例、展示数据的分布情况等。
# 饼图
# 环形图
# 南丁格尔玫瑰图
# 半环形图
# 圆角环形图
# 矩形树图
矩形树图(Treemap)是一种用于展示层次结构数据的可视化图表,通过嵌套矩形来表示数据的层级关系和占比情况。

# 树图
树图(Tree Diagram)是一种用于表示数据或信息层次结构的图形化工具。它以树状结构展示元素之间的关系。
# 左右树图

# 上下树图
# 折线树图

# 径向树状图
# 桑基图
桑基图(Sankey Diagram)是一种特殊的流向图,用于展示数据的流动和转换过程。它通过宽度不等的箭头或带状线条来表示数据的流向和数量,箭头的宽度通常与数据的大小成正比。
# 桑基图
# 垂直桑基图
# 漏斗图
漏斗图(Funnel Chart)用于展示数据在不同阶段的逐步减少或筛选过程。
# 漏斗图
# 仪表盘
仪表盘图是一种综合性的可视化界面,它将多个图表和指标整合在一起,提供一个全面的数据概览。仪表盘图的设计目标是让用户能够快速获取关键信息。
# 基础仪表盘
# 等级仪表盘
# 多标题仪表盘
# 数据分析方法说明
# 描述性分析
# 描述
- 应用场景
对于定量数据,比如量表评分、身高体重数值,可以通过描述性分析计算数据的集中性特征、波动性特征,系统提供最大最小值、中位数值、众数、偏度、峰度等常用统计特征值,以及分位数的值和箱线图。
- 输入参数
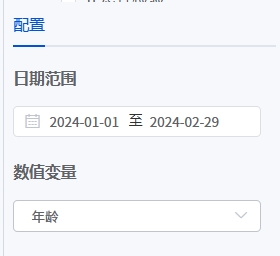
- 输出结果

# 频数分析
- 应用场景
频数分析是统计每个数据值或数据范围出现的次数,通常用于了解数据的分布情况。如分析某种疾病的分布情况,例如,统计不同地区、不同年龄段的患者数量。
- 输入参数
- 输出结果
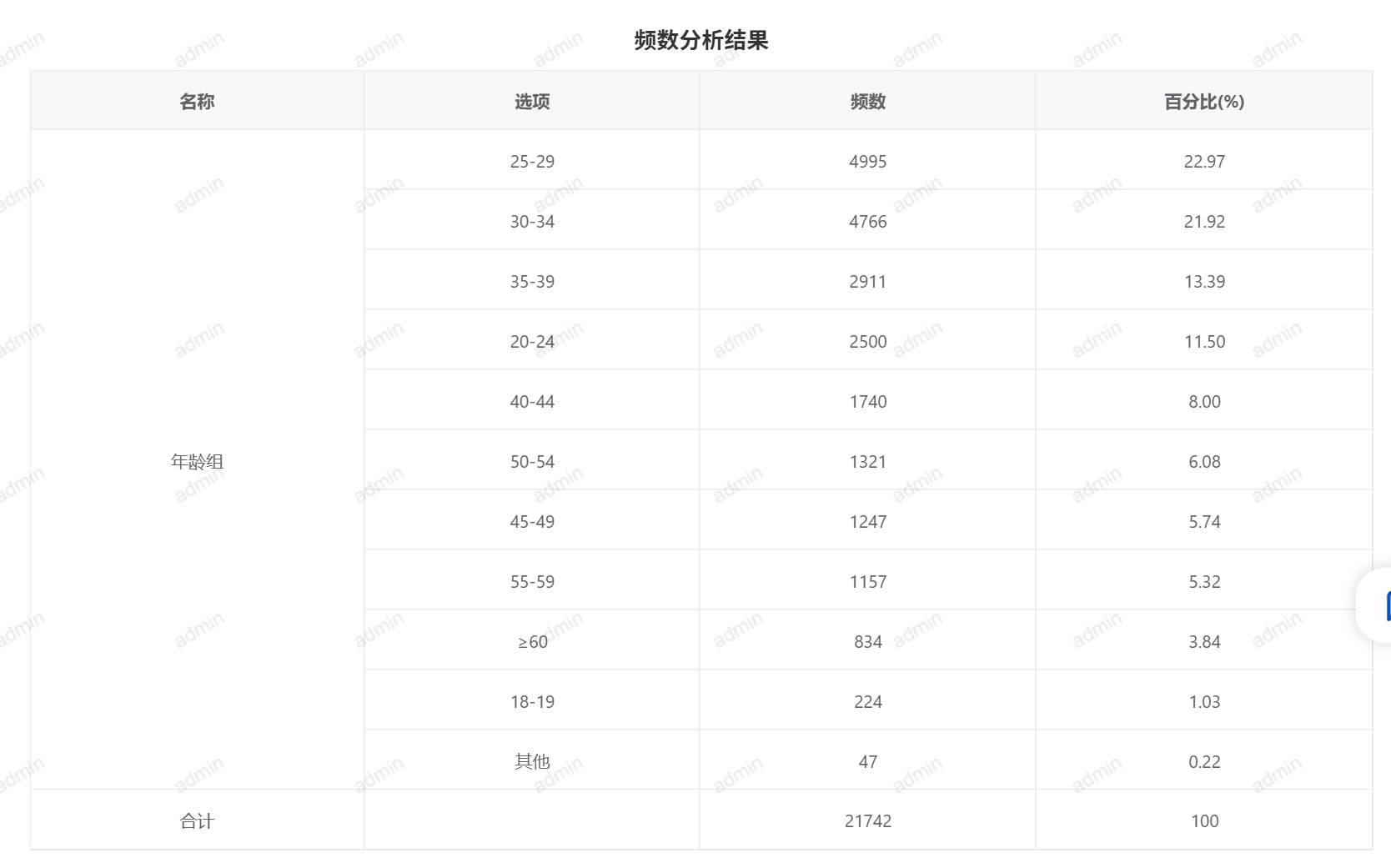
# 分类汇总
- 应用场景
分类汇总是将数据按某一分类标准进行分组,并对每个组进行汇总计算,如求和、平均值、最大值等。
- 输入参数
- 输出结果
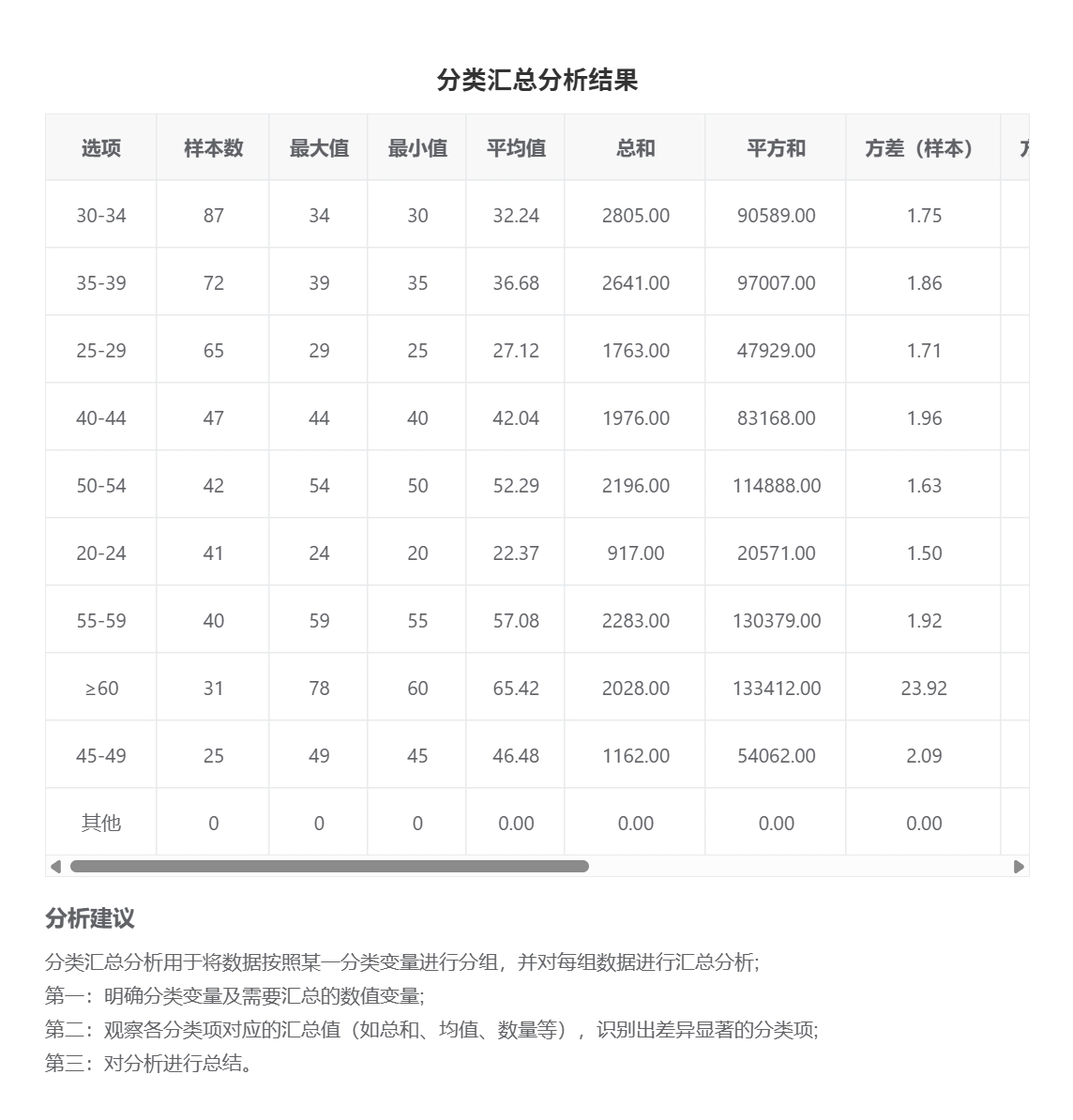
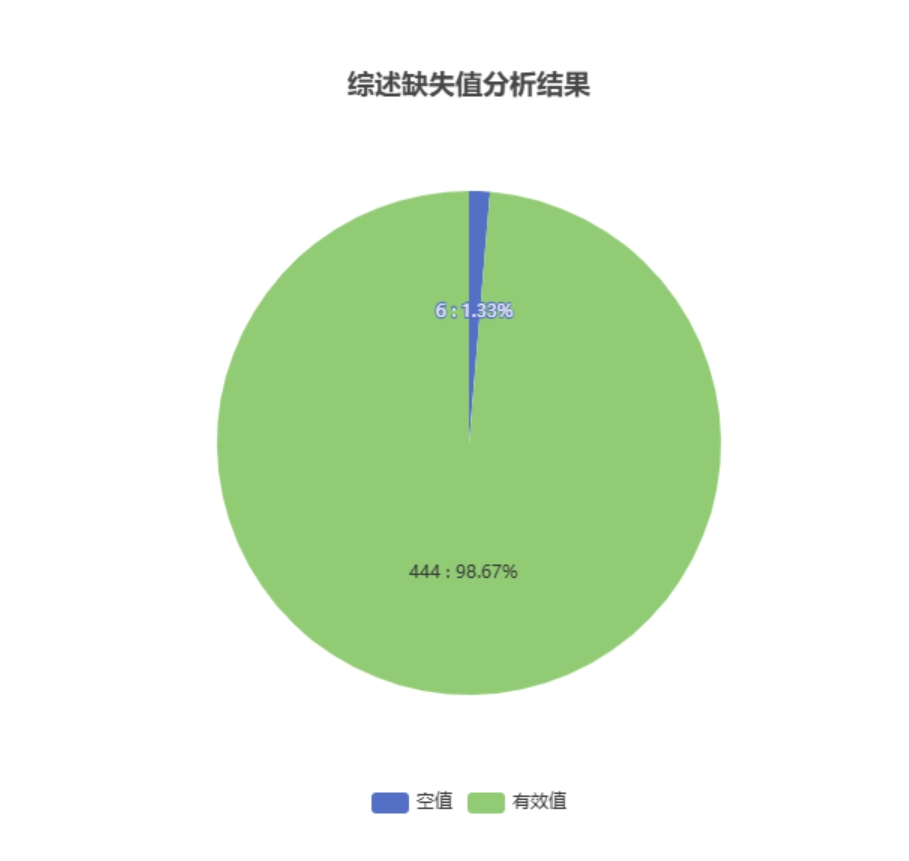
# 缺失值分析
- 应用场景
缺失值分析是识别和处理数据集中缺失数据的过程,以确保数据的完整性和分析结果的准确性。
- 输入参数
- 输出结果
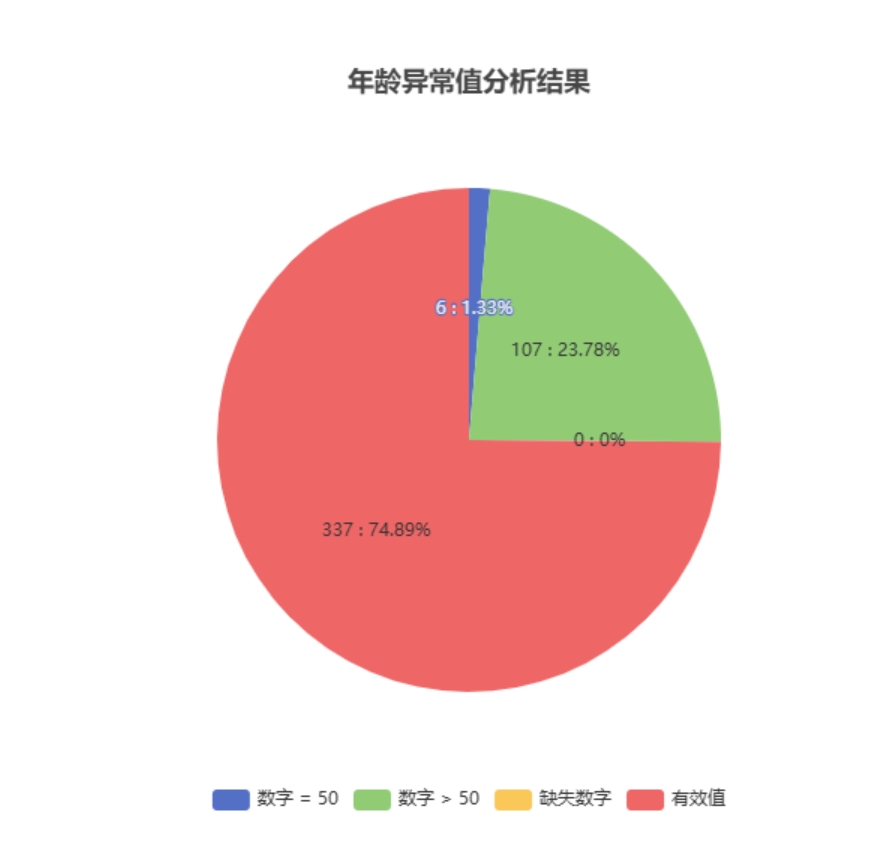
# 异常值分析
- 应用场景
异常值分析是识别数据集中不符合正常分布规律的极端数据点的过程,这些数据点可能由错误、异常事件或特殊情况引起。
- 输入参数
- 输出结果
# 参数分析
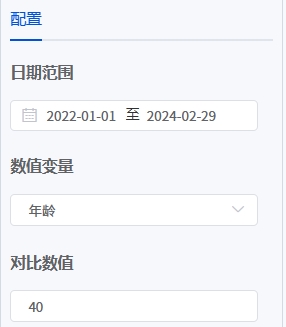
# 单样本t检验
- 应用场景
单样本t 检验用于分析定量数据是否与某个数字有着显著的差异性,比如五级量表,3分代表中立态度,可以使用单样本t 检验分析样本的态度是否明显不为中立状态;系统默认以0分进行对比。
适用于以下情况:
- 只有一个样本数据集。
- 已知总体均值(或设定的比较值)。
- 样本数据服从正态分布(或样本量较大时,根据中心极限定理可以近似正态分布)。
- 输入参数
- 输出结果说明

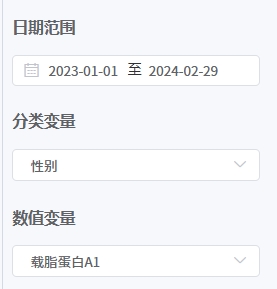
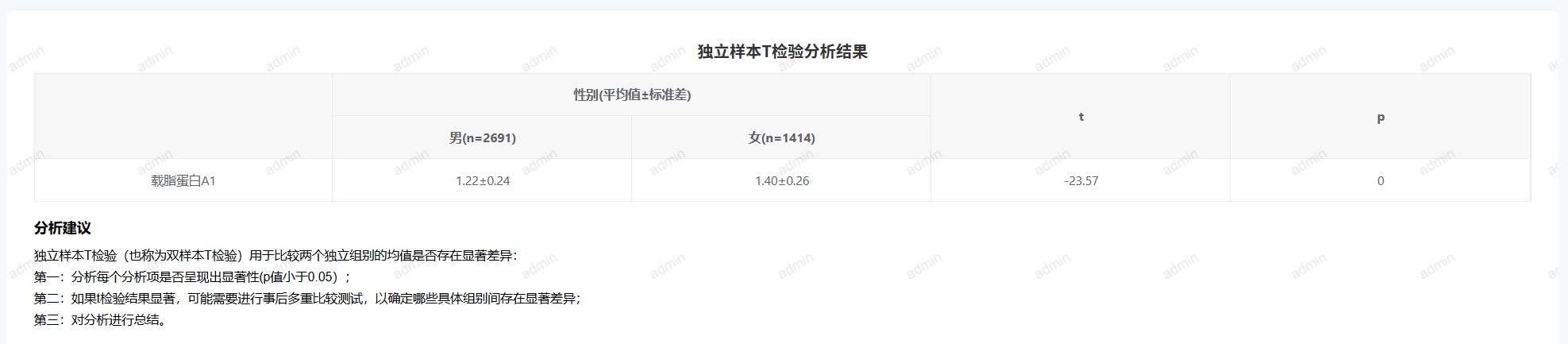
# 独立样本t检验
- 应用场景
用于检验两个独立样本的均值是否存在显著差异。例如,比较两种不同医疗方法下治疗效果的差异,或者比较男性和女性在某项指标上的差异。
适用于以下情况:
- 有两个独立的样本数据集(即两个样本之间没有关联)。
- 每个样本数据服从正态分布(或样本量较大时可以近似正态分布)。
- 两个样本的方差可以相等或不相等。
- 输入参数
- 输出结果说明
# 配对样本t检验
- 应用场景
配对样本t检验(Paired Sample t-Test)主要用于比较两组相关样本的均值是否存在显著差异。其核心目的是通过分析配对数据的差异,判断某种处理或干预是否对结果产生了显著影响。
适用于以下情况:
- 数据是成对的:每个样本中的观测值与另一个样本中的观测值存在一一对应关系。
- 样本来自同一总体或相关总体:例如,同一组受试者在不同时间点或条件下的测量。
- 数据满足正态性假设:配对样本t检验要求差值数据服从正态分布,或者样本量较大时可以近似正态分布。
- 控制个体差异:通过配对设计,可以消除个体间的差异对结果的影响,从而更准确地评估处理或干预的效果
- 输入参数
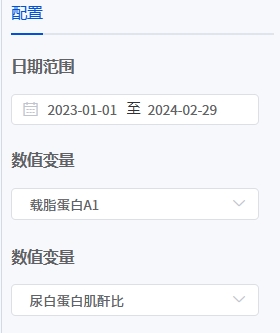
- 输出结果说明

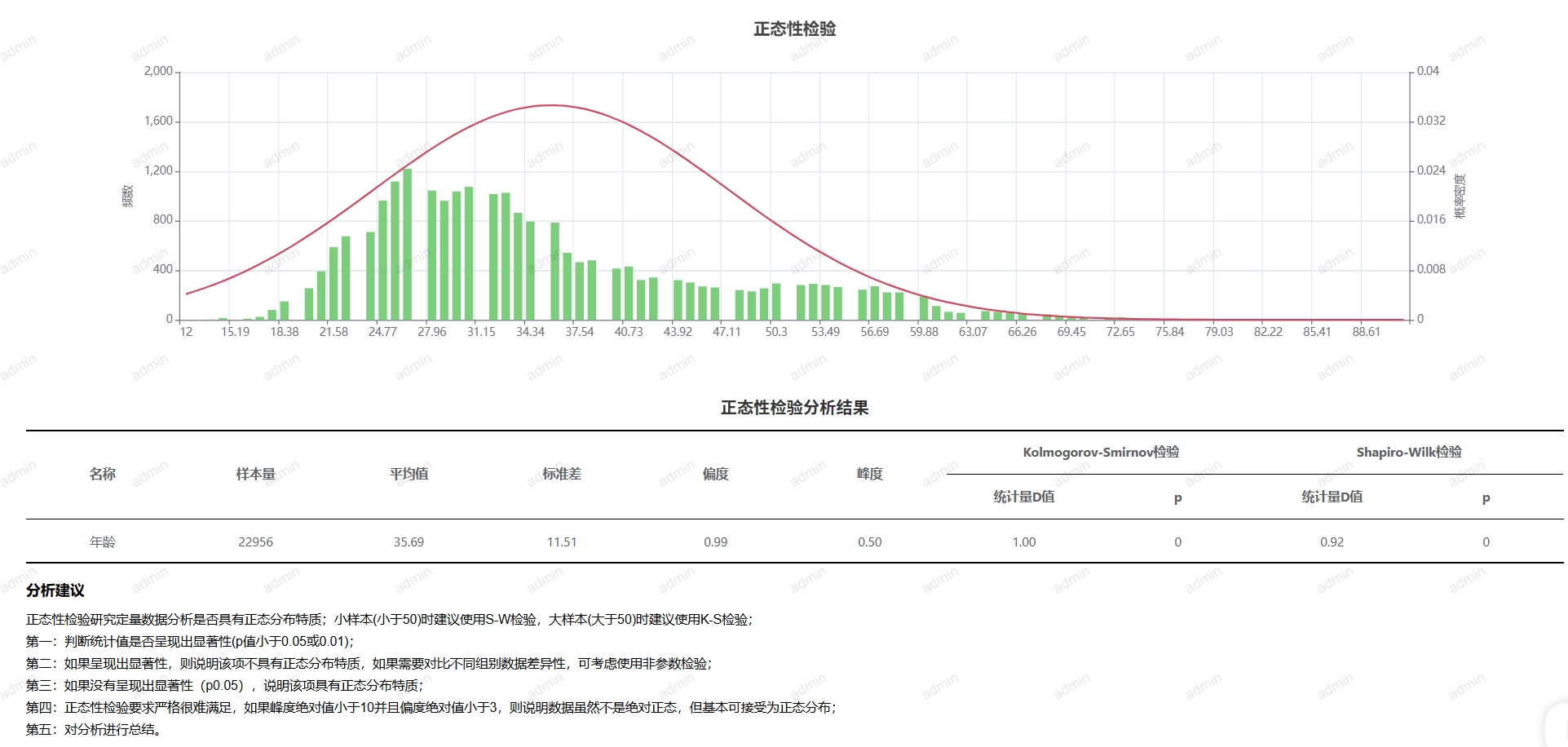
# 正态性检验
- 应用场景
正态性检验的主要目的是判断一组数据是否服从正态分布(高斯分布)。这一检验在统计分析中具有重要意义,因为许多统计方法和模型(如t检验、方差分析、回归分析等)都依赖于数据的正态性假设。
- 输入参数
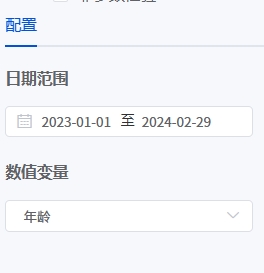
- 输出结果说明
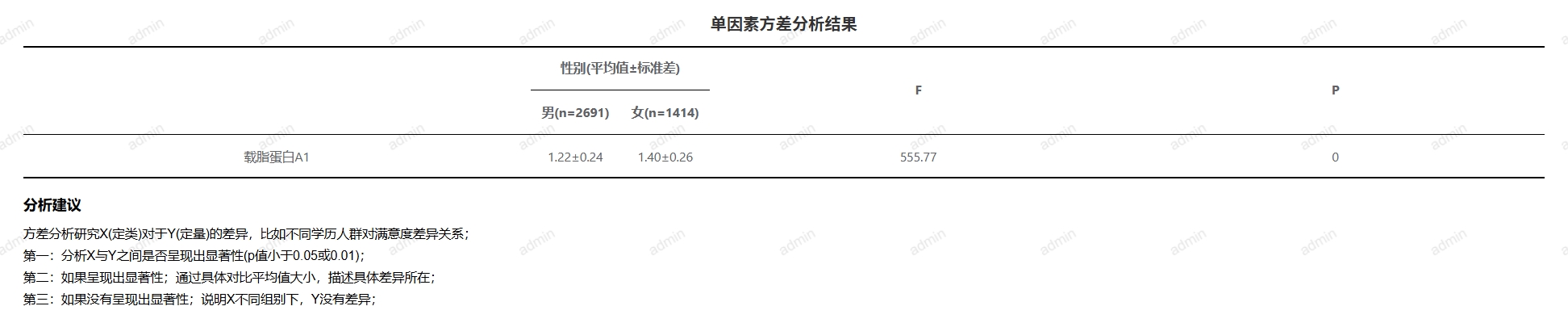
# 单因素方差分析
- 应用场景
单因素方差分析(One-Way ANOVA)是一种统计方法,用于检验一个自变量(因子)在多个水平(组别)下对一个连续因变量的影响,即判断这些组的均值是否存在显著差异。
单因素方差分析适用于以下场景:
- 一个自变量多个水平:当研究中只有一个自变量,但该变量有多个水平(组别)时,可以使用单因素方差分析。
- 因变量为连续数据:因变量必须是连续的数值型数据。
- 满足基本假设:
- 正态性:各组数据应服从正态分布。
- 方差齐性:各组的方差应相等。
- 独立性:各组数据之间应相互独立。
- 完全随机设计的数据:适用于完全随机设计的实验数据,即每个样本随机分配到不同的组别。
注意事项:
- 数据正态性:如果数据不满足正态性假设,可以考虑数据转换或使用非参数检验(如Kruskal-Wallis检验)。
- 方差齐性:通过Levene检验等方法验证方差齐性。如果方差不齐,可以使用Welch检验。
- 多重比较:如果ANOVA结果显示显著差异,需要进一步进行多重比较(如Tukey HSD、Bonferroni校正)以确定哪些组之间存在显著差异。
- 输入参数
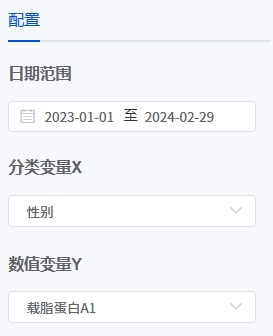
- 输出结果
# 非参数分析
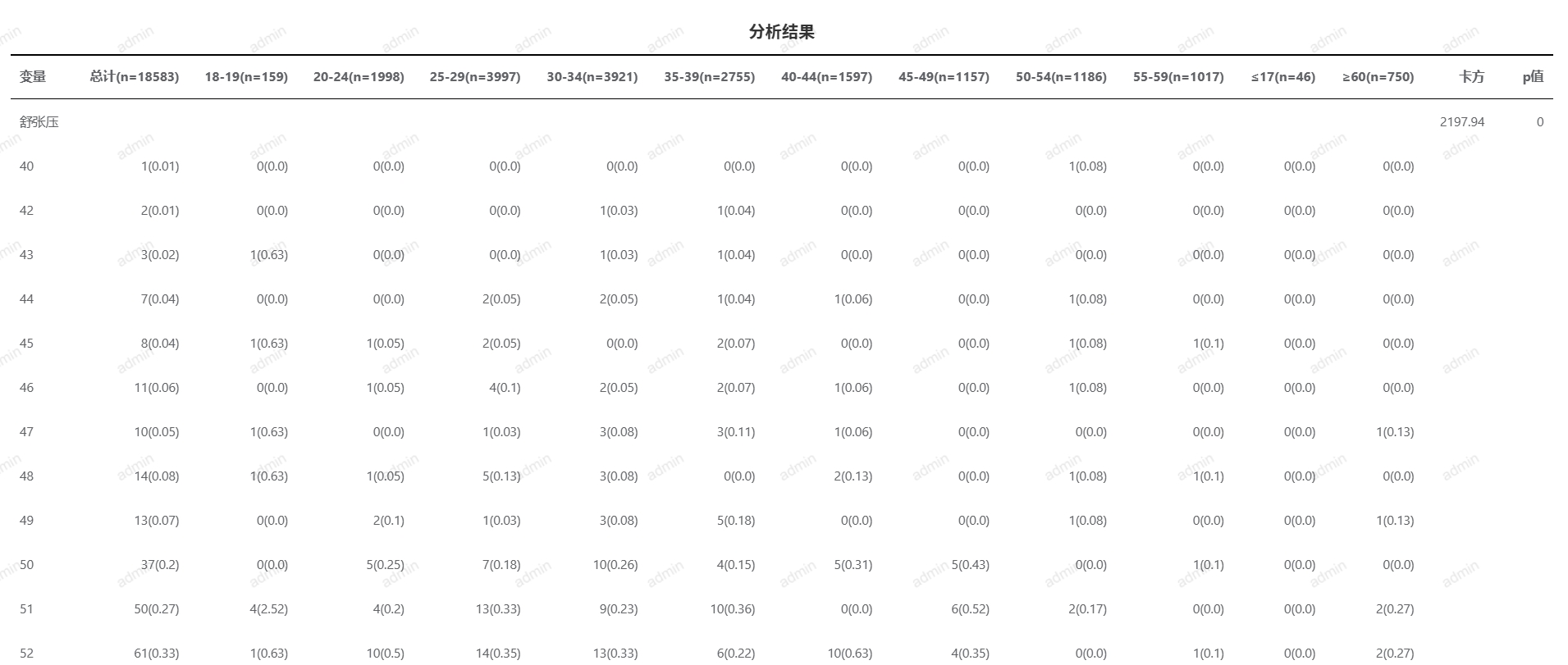
# 卡方检验
- 应用场景
- 检验独立性:判断两个分类变量之间是否存在显著的关联关系。例如,研究性别(男/女)与产品偏好(喜欢/不喜欢)之间是否存在关联。
- 检验拟合优度(Goodness of Fit):判断一组观测数据是否符合某种理论分布。例如,检验骰子的投掷结果是否符合均匀分布。
- 检验同质性(Homogeneity):判断多个总体的分布是否一致。例如,比较不同城市对某一菜单项的偏好是否一致。
- 检验比例差异:判断不同组之间的比例是否存在显著差异。例如,比较不同治疗方法的有效率是否有差异
- 输入参数
- 输出结果说明
# 非参数检验
- 应用场景
Mann-Whitney U检验(也称为Wilcoxon秩和检验)是一种非参数统计方法,用于比较两个独立样本的分布是否存在显著差异。它特别适用于数据不满足正态分布假设的情况,是t检验的非参数替代方法。该检验通过比较两组数据的秩和来判断一组数据是否倾向于比另一组更大或更小。
Kruskal-Wallis检验是一种非参数统计方法,用于比较三个或更多独立组的中位数是否存在显著差异。它是单因素方差分析(ANOVA)的非参数替代方法,适用于数据不满足正态分布或方差齐性假设的情况。
如果X的组别为两组,则应该使用MannWhitney统计量,如果组别超过两组,则应该使用Kruskal-Wallis统计量结果。系统自动选择MannWhitney或者Kruskal-Wallis统计量。
- 输入参数
- 输出结果说明

# Fisher精确检验
- 应用场景
Fisher精确检验是一种用于分析分类数据的统计显著性检验方法,主要用于判断两个分类变量之间是否存在显著的关联性。其核心目的是通过计算在零假设(两个变量独立)成立的情况下,观察到当前数据或更极端情况的概率(P值),从而判断变量之间是否存在非随机的关联。
适用场景
- 小样本数据:当样本量较小时(如总样本量n < 40),或列联表中任一单元格的期望频数小于5时,Fisher精确检验是更合适的选择。
- 稀疏数据:在数据稀疏的情况下(如罕见疾病的病例对照研究),Fisher精确检验能够提供更准确的统计推断。
- 2×2列联表:Fisher精确检验最初设计用于2×2列联表,但也可以扩展到更大的列联表。
- 分类变量分析:适用于分析两个分类变量之间的关系,例如性别与疾病发生、治疗方法与疗效等。
- 需要精确P值的情况:与卡方检验相比,Fisher精确检验不依赖于大样本近似,能够提供更精确的P值。
- 输入参数
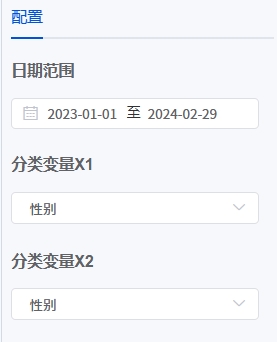
- 输出结果说明

# 相关分析
# Pearson相关分析
- 应用场景
Pearson相关分析(Pearson Correlation Analysis)是一种用于衡量两个连续变量之间线性关系强度和方向的统计方法。其主要目的是:
- 评估线性关系:通过计算Pearson相关系数(r),量化两个变量之间的线性相关性。
- r 的取值范围为 [−1,1]:
- r=1:完全正相关(一个变量增加,另一个变量也增加)。
- r=−1:完全负相关(一个变量增加,另一个变量减少)。
- r=0:无线性相关。
- r 的取值范围为 [−1,1]:
- 确定关系的方向和强度:正相关系数表示正向关系,负相关系数表示负向关系;系数的绝对值越接近1,表示线性关系越强。
- 为后续分析提供基础:相关分析的结果可以为回归分析、因果关系研究等提供初步依据。
Pearson相关分析适用于以下场景:
- 连续变量:两个变量都应是连续的(如身高、体重、收入、成绩等)。
- 线性关系:变量之间存在线性关系。如果关系是非线性的,Pearson相关系数可能无法准确反映相关性。
- 正态分布:虽然不要求严格正态分布,但数据接近正态分布时,相关分析的结果更可靠。
- 独立性:观测值之间应相互独立,即一个观测值的结果不应影响另一个观测值。
- 无异常值:数据中不应存在极端异常值,因为异常值会对相关系数产生较大影响。
- 输入参数
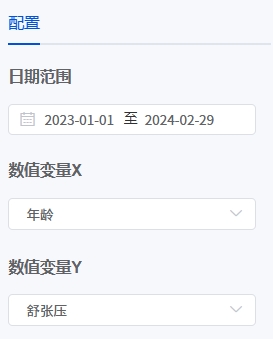
- 输出结果说明

# 回归分析
# 一元线性回归
- 应用场景
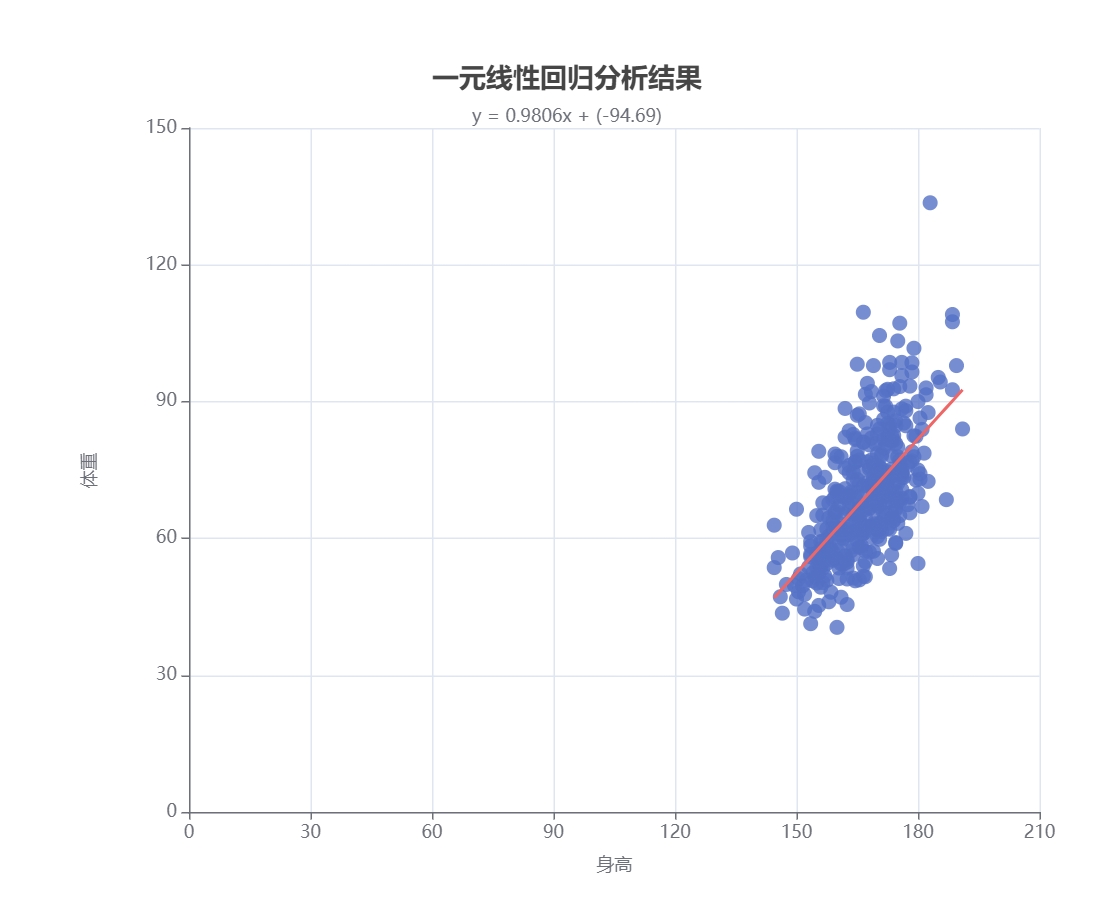
一元线性回归是一种统计分析方法,用于研究一个自变量(解释变量)与一个因变量(被解释变量)之间的线性关系。在医学领域的应用场景包括:
药物疗效:分析药物剂量与治疗效果之间的关系。例如,研究某种药物的剂量与患者康复时间之间的线性关系。 健康风险:分析生活方式因素(如吸烟、饮酒)与健康指标(如血压、胆固醇水平)之间的关系。例如,研究吸烟量与肺癌发病率之间的关系。 疾病预测:分析环境因素与疾病发生率之间的关系。例如,研究空气污染水平与呼吸系统疾病发病率之间的关系
- 输入参数
输出结果说明
![数据分析-一元线性-输出]()
# 二元Logistics回归
- 应用场景
二元Logistics回归是一种用于分析二分类因变量(如患病/健康、阳性/阴性)与一个或多个自变量之间关系的统计方法。它在医学领域有广泛的应用,主要用于疾病预测、危险因素分析、诊断辅助等方面。如:用于预测患者是否患有某种疾病、帮助识别和量化影响疾病发生的危险因素等。
- 输入参数
输出结果说明
![数据分析-二元Log-输出]()

# 多元Logistics回归
- 应用场景
多元Logistic回归是一种用于分析多个自变量对一个因变量(通常是分类变量)影响的统计方法。在医学领域,它被广泛应用于疾病风险评估、危险因素分析、诊断辅助、预后预测等多个方面。
- 输入参数
输出结果说明
![数据分析-多元log-输出1]()